MAR: Masked Autoencoders for Efficient Action Recognition
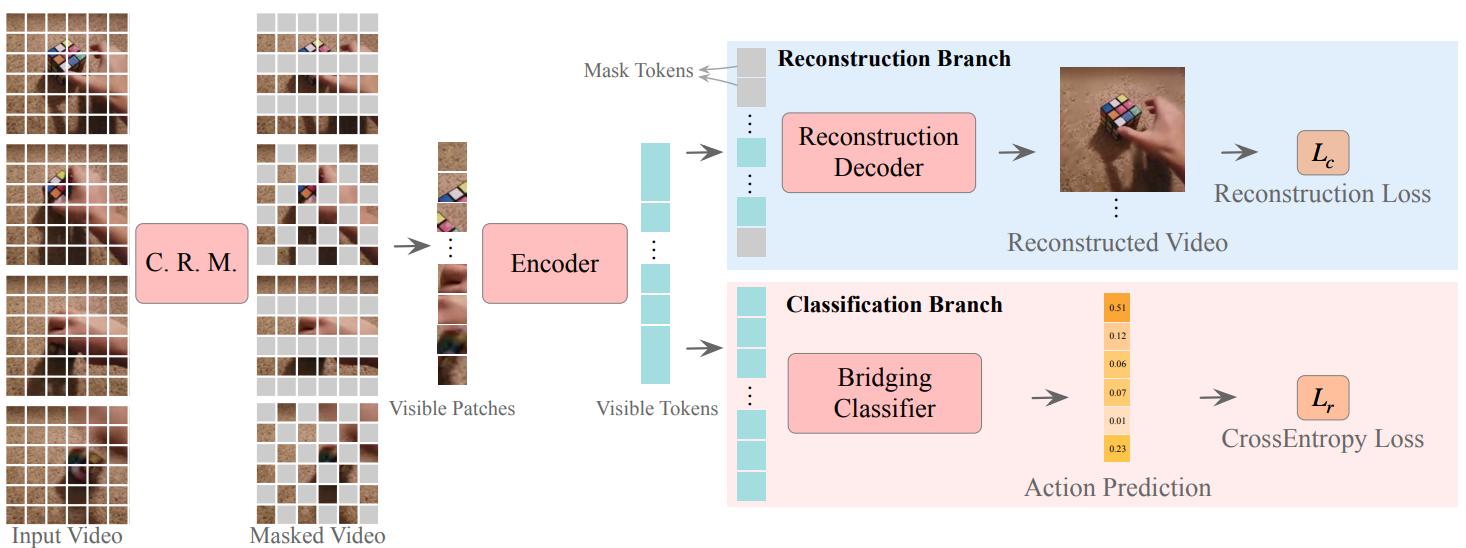
Standard approaches for video recognition usually operate on the full input videos, which is inefficient due to the widely present spatio-temporal redundancy in videos. Recent progress in masked video modelling, i.e., VideoMAE, has shown the ability of vanilla Vision Transformers (ViT) to complement spatio-temporal contexts given only limited visual contents. Inspired by this, we propose propose Masked Action Recognition (MAR), which reduces the redundant computation by discarding a proportion of patches and operating only on a part of the videos. MAR contains the following two indispensable components: cell running masking and bridging classifier. Specifically, to enable the ViT to perceive the details beyond the visible patches easily, cell running masking is presented to preserve the spatio-temporal correlations in videos, which ensures the patches at the same spatial location can be observed in turn for easy reconstructions. Additionally, we notice that, although the partially observed features can reconstruct semantically explicit invisible patches, they fail to achieve accurate classification. To address this, a bridging classifier is proposed to bridge the semantic gap between the ViT encoded features for reconstruction and the features specialized for classification. Our proposed MAR reduces the computational cost of ViT by 53% and extensive experiments show that MAR consistently outperforms existing ViT models with a notable margin. Especially, we found a ViT-Large trained by MAR outperforms the ViT-Huge trained by a standard training scheme by convincing margins on both Kinetics-400 and Something-Something v2 datasets, while our computation overhead of ViT-Large is only 14.5% of ViT-Huge.
PDF Abstract



 ImageNet
ImageNet
 UCF101
UCF101
 Kinetics
Kinetics
 HMDB51
HMDB51
 Kinetics 400
Kinetics 400
 Something-Something V2
Something-Something V2

