Mask2Former for Video Instance Segmentation
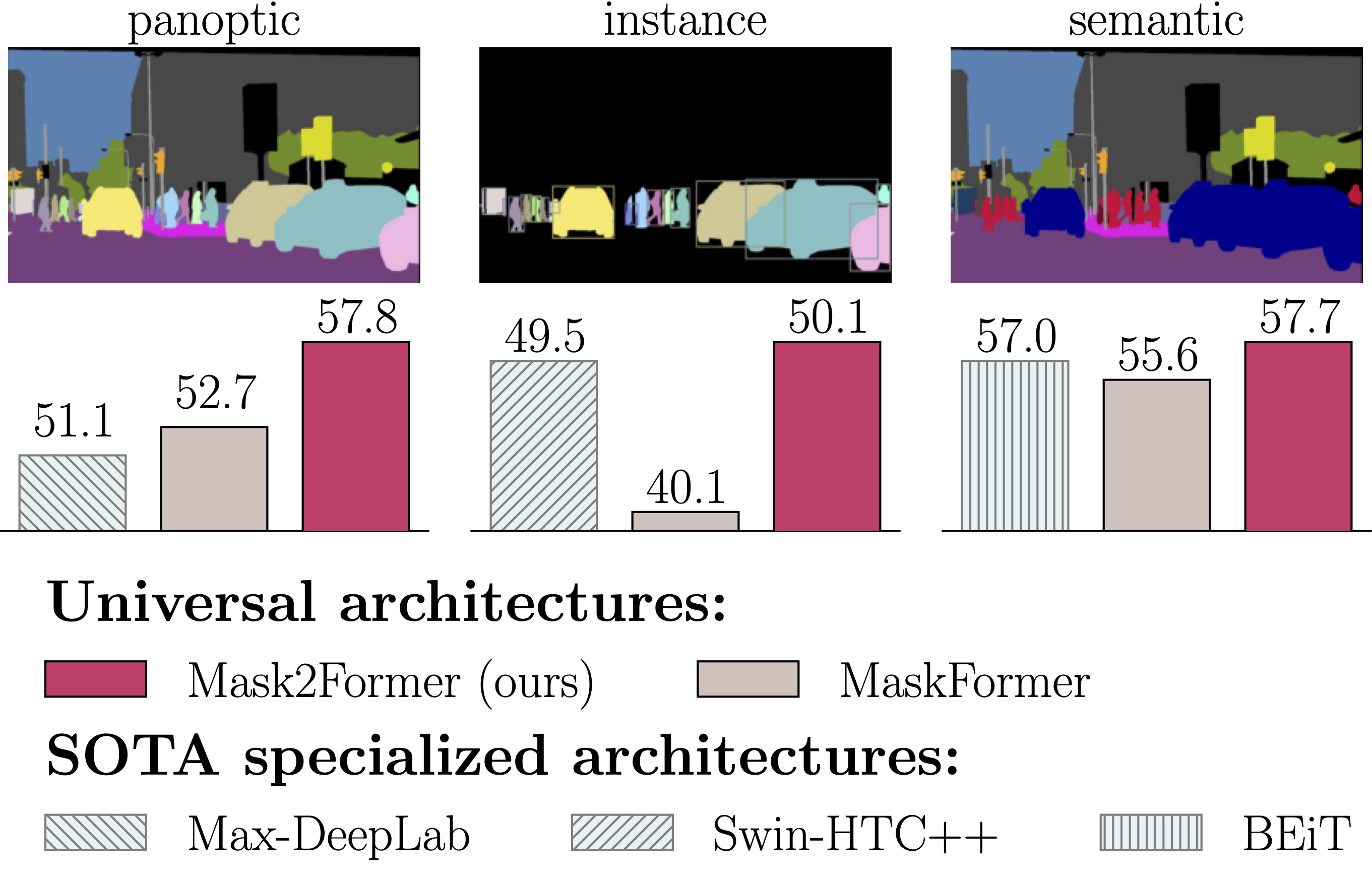
We find Mask2Former also achieves state-of-the-art performance on video instance segmentation without modifying the architecture, the loss or even the training pipeline. In this report, we show universal image segmentation architectures trivially generalize to video segmentation by directly predicting 3D segmentation volumes. Specifically, Mask2Former sets a new state-of-the-art of 60.4 AP on YouTubeVIS-2019 and 52.6 AP on YouTubeVIS-2021. We believe Mask2Former is also capable of handling video semantic and panoptic segmentation, given its versatility in image segmentation. We hope this will make state-of-the-art video segmentation research more accessible and bring more attention to designing universal image and video segmentation architectures.
PDF AbstractCode
 Colab
Colab
 Spaces
Spaces
 Replicate
Replicate






Datasets
 YouTube-VIS 2019
YouTube-VIS 2019
 OVIS
OVIS
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Video Instance Segmentation | OVIS validation | Mask2Former-VIS | mask AP | 16.6 | # 37 | |
| AP50 | 36.9 | # 32 | ||||
| AP75 | 14.1 | # 36 | ||||
| AR1 | 9.9 | # 27 | ||||
| AR10 | 24.7 | # 27 | ||||
| Video Instance Segmentation | YouTube-VIS validation | Mask2Former (Swin-L) | mask AP | 60.4 | # 14 | |
| AP50 | 84.4 | # 12 | ||||
| AP75 | 67.0 | # 13 | ||||
| Video Instance Segmentation | YouTube-VIS validation | Mask2Former (ResNet-50) | mask AP | 46.4 | # 28 | |
| AP50 | 68.0 | # 27 | ||||
| AP75 | 50.0 | # 27 | ||||
| Video Instance Segmentation | YouTube-VIS validation | Mask2Former (ResNet-101) | mask AP | 49.2 | # 24 | |
| AP50 | 72.8 | # 22 | ||||
| AP75 | 54.2 | # 23 |
