Masked Distillation with Receptive Tokens
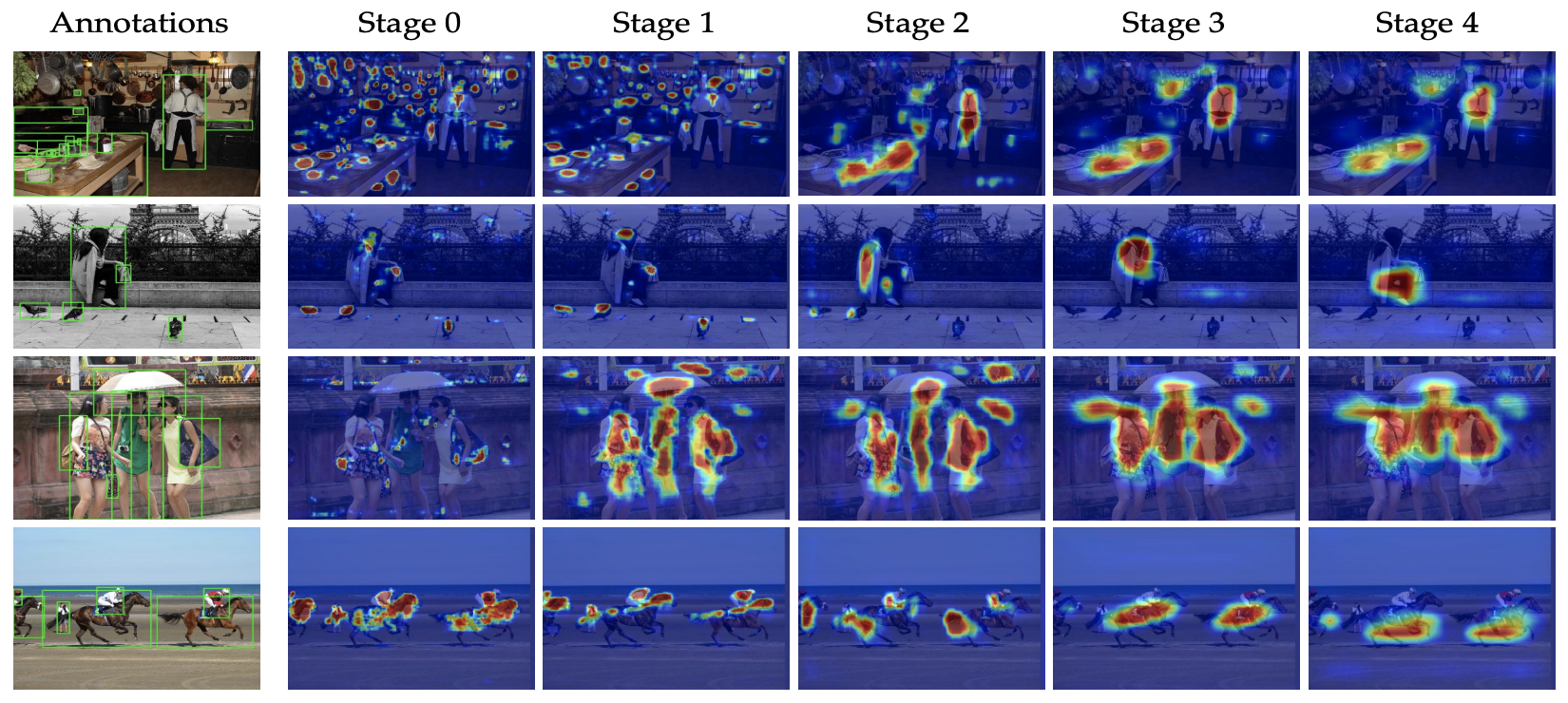
Distilling from the feature maps can be fairly effective for dense prediction tasks since both the feature discriminability and localization priors can be well transferred. However, not every pixel contributes equally to the performance, and a good student should learn from what really matters to the teacher. In this paper, we introduce a learnable embedding dubbed receptive token to localize those pixels of interests (PoIs) in the feature map, with a distillation mask generated via pixel-wise attention. Then the distillation will be performed on the mask via pixel-wise reconstruction. In this way, a distillation mask actually indicates a pattern of pixel dependencies within feature maps of teacher. We thus adopt multiple receptive tokens to investigate more sophisticated and informative pixel dependencies to further enhance the distillation. To obtain a group of masks, the receptive tokens are learned via the regular task loss but with teacher fixed, and we also leverage a Dice loss to enrich the diversity of learned masks. Our method dubbed MasKD is simple and practical, and needs no priors of tasks in application. Experiments show that our MasKD can achieve state-of-the-art performance consistently on object detection and semantic segmentation benchmarks. Code is available at: https://github.com/hunto/MasKD .
PDF Abstract



 MS COCO
MS COCO
 Cityscapes
Cityscapes
