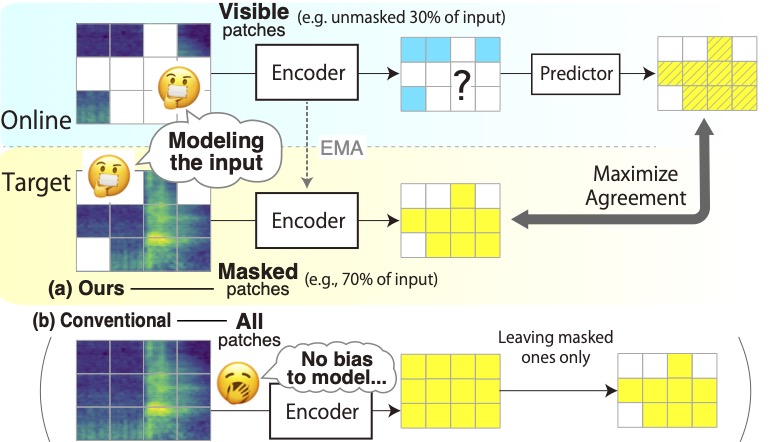
Masked Modeling Duo: Learning Representations by Encouraging Both Networks to Model the Input
Masked Autoencoders is a simple yet powerful self-supervised learning method. However, it learns representations indirectly by reconstructing masked input patches. Several methods learn representations directly by predicting representations of masked patches; however, we think using all patches to encode training signal representations is suboptimal. We propose a new method, Masked Modeling Duo (M2D), that learns representations directly while obtaining training signals using only masked patches. In the M2D, the online network encodes visible patches and predicts masked patch representations, and the target network, a momentum encoder, encodes masked patches. To better predict target representations, the online network should model the input well, while the target network should also model it well to agree with online predictions. Then the learned representations should better model the input. We validated the M2D by learning general-purpose audio representations, and M2D set new state-of-the-art performance on tasks such as UrbanSound8K, VoxCeleb1, AudioSet20K, GTZAN, and SpeechCommandsV2. We additionally validate the effectiveness of M2D for images using ImageNet-1K in the appendix.
PDF AbstractCode
 Colab
Colab




 VoxCeleb1
VoxCeleb1
 AudioSet
AudioSet
 Speech Commands
Speech Commands
 ESC-50
ESC-50
 UrbanSound8K
UrbanSound8K
 NSynth
NSynth
 VoxForge
VoxForge
Results from the Paper
 Ranked #1 on
Speaker Identification
on VoxCeleb1
(using extra training data)
Ranked #1 on
Speaker Identification
on VoxCeleb1
(using extra training data)
