MASS: Masked Sequence to Sequence Pre-training for Language Generation
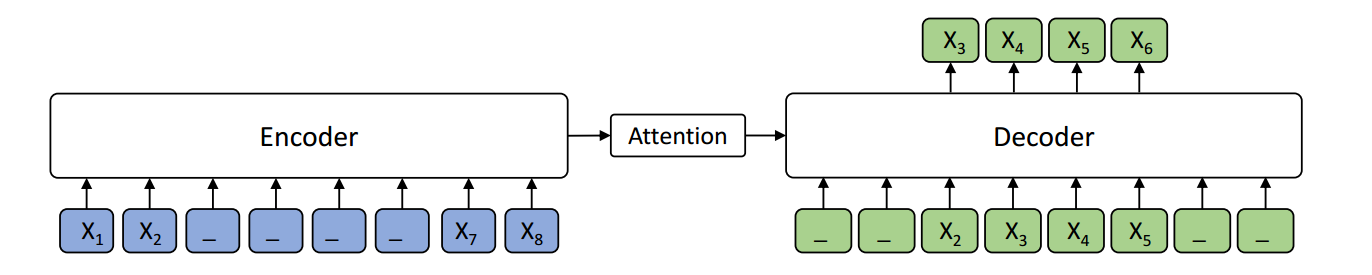
Pre-training and fine-tuning, e.g., BERT, have achieved great success in language understanding by transferring knowledge from rich-resource pre-training task to the low/zero-resource downstream tasks. Inspired by the success of BERT, we propose MAsked Sequence to Sequence pre-training (MASS) for the encoder-decoder based language generation tasks. MASS adopts the encoder-decoder framework to reconstruct a sentence fragment given the remaining part of the sentence: its encoder takes a sentence with randomly masked fragment (several consecutive tokens) as input, and its decoder tries to predict this masked fragment. In this way, MASS can jointly train the encoder and decoder to develop the capability of representation extraction and language modeling. By further fine-tuning on a variety of zero/low-resource language generation tasks, including neural machine translation, text summarization and conversational response generation (3 tasks and totally 8 datasets), MASS achieves significant improvements over the baselines without pre-training or with other pre-training methods. Specially, we achieve the state-of-the-art accuracy (37.5 in terms of BLEU score) on the unsupervised English-French translation, even beating the early attention-based supervised model.
PDF Abstract







 SQuAD
SQuAD
 WMT 2014
WMT 2014
 WMT 2016
WMT 2016
 WMT 2016 News
WMT 2016 News
