MatchFormer: Interleaving Attention in Transformers for Feature Matching
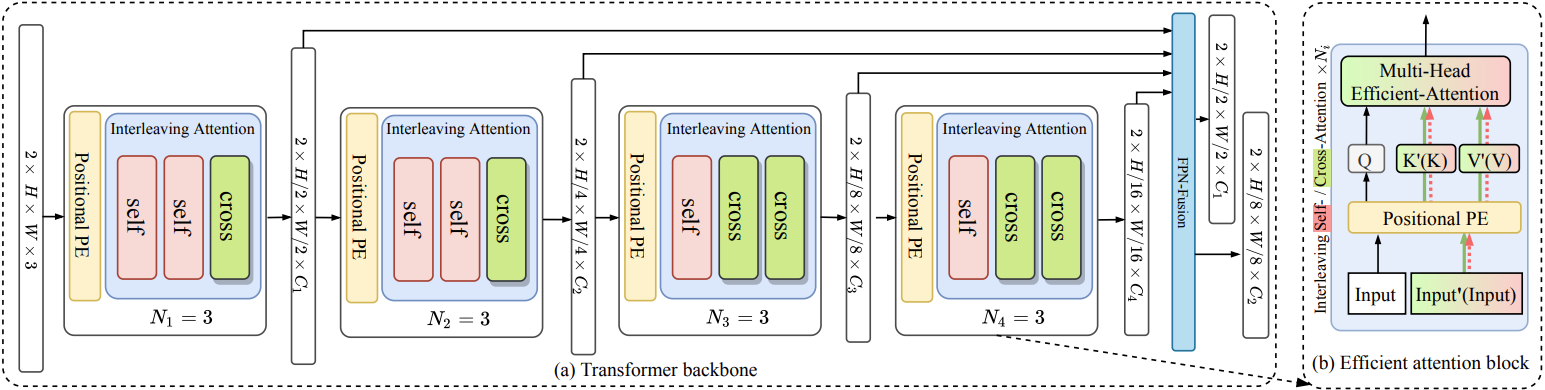
Local feature matching is a computationally intensive task at the subpixel level. While detector-based methods coupled with feature descriptors struggle in low-texture scenes, CNN-based methods with a sequential extract-to-match pipeline, fail to make use of the matching capacity of the encoder and tend to overburden the decoder for matching. In contrast, we propose a novel hierarchical extract-and-match transformer, termed as MatchFormer. Inside each stage of the hierarchical encoder, we interleave self-attention for feature extraction and cross-attention for feature matching, yielding a human-intuitive extract-and-match scheme. Such a match-aware encoder releases the overloaded decoder and makes the model highly efficient. Further, combining self- and cross-attention on multi-scale features in a hierarchical architecture improves matching robustness, particularly in low-texture indoor scenes or with less outdoor training data. Thanks to such a strategy, MatchFormer is a multi-win solution in efficiency, robustness, and precision. Compared to the previous best method in indoor pose estimation, our lite MatchFormer has only 45% GFLOPs, yet achieves a +1.3% precision gain and a 41% running speed boost. The large MatchFormer reaches state-of-the-art on four different benchmarks, including indoor pose estimation (ScanNet), outdoor pose estimation (MegaDepth), homography estimation and image matching (HPatch), and visual localization (InLoc).
PDF Abstract


 ScanNet
ScanNet
 HPatches
HPatches
 MegaDepth
MegaDepth
 InLoc
InLoc
