Maximum Entropy Deep Inverse Reinforcement Learning
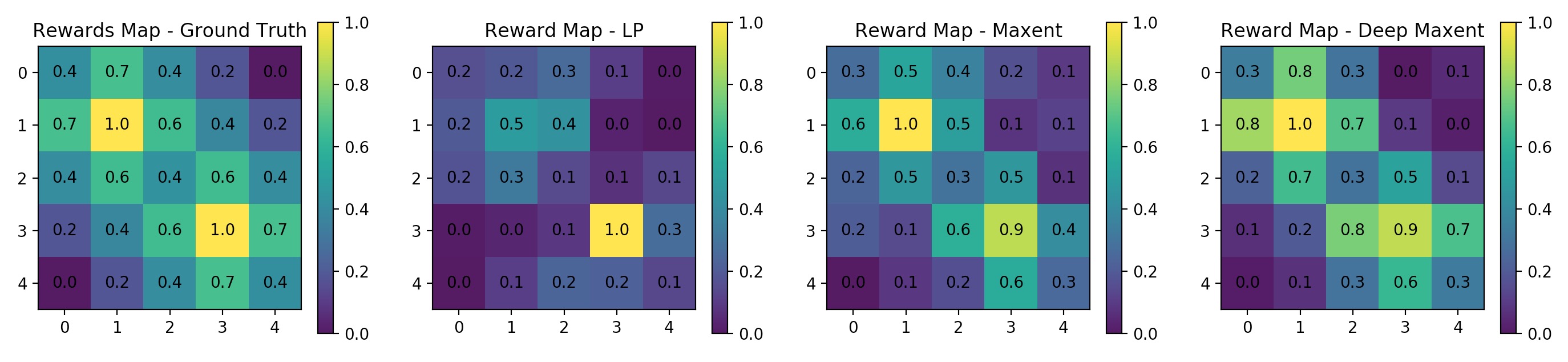
This paper presents a general framework for exploiting the representational capacity of neural networks to approximate complex, nonlinear reward functions in the context of solving the inverse reinforcement learning (IRL) problem. We show in this context that the Maximum Entropy paradigm for IRL lends itself naturally to the efficient training of deep architectures. At test time, the approach leads to a computational complexity independent of the number of demonstrations, which makes it especially well-suited for applications in life-long learning scenarios. Our approach achieves performance commensurate to the state-of-the-art on existing benchmarks while exceeding on an alternative benchmark based on highly varying reward structures. Finally, we extend the basic architecture - which is equivalent to a simplified subclass of Fully Convolutional Neural Networks (FCNNs) with width one - to include larger convolutions in order to eliminate dependency on precomputed spatial features and work on raw input representations.
PDF Abstract

