MEANTIME: Mixture of Attention Mechanisms with Multi-temporal Embeddings for Sequential Recommendation
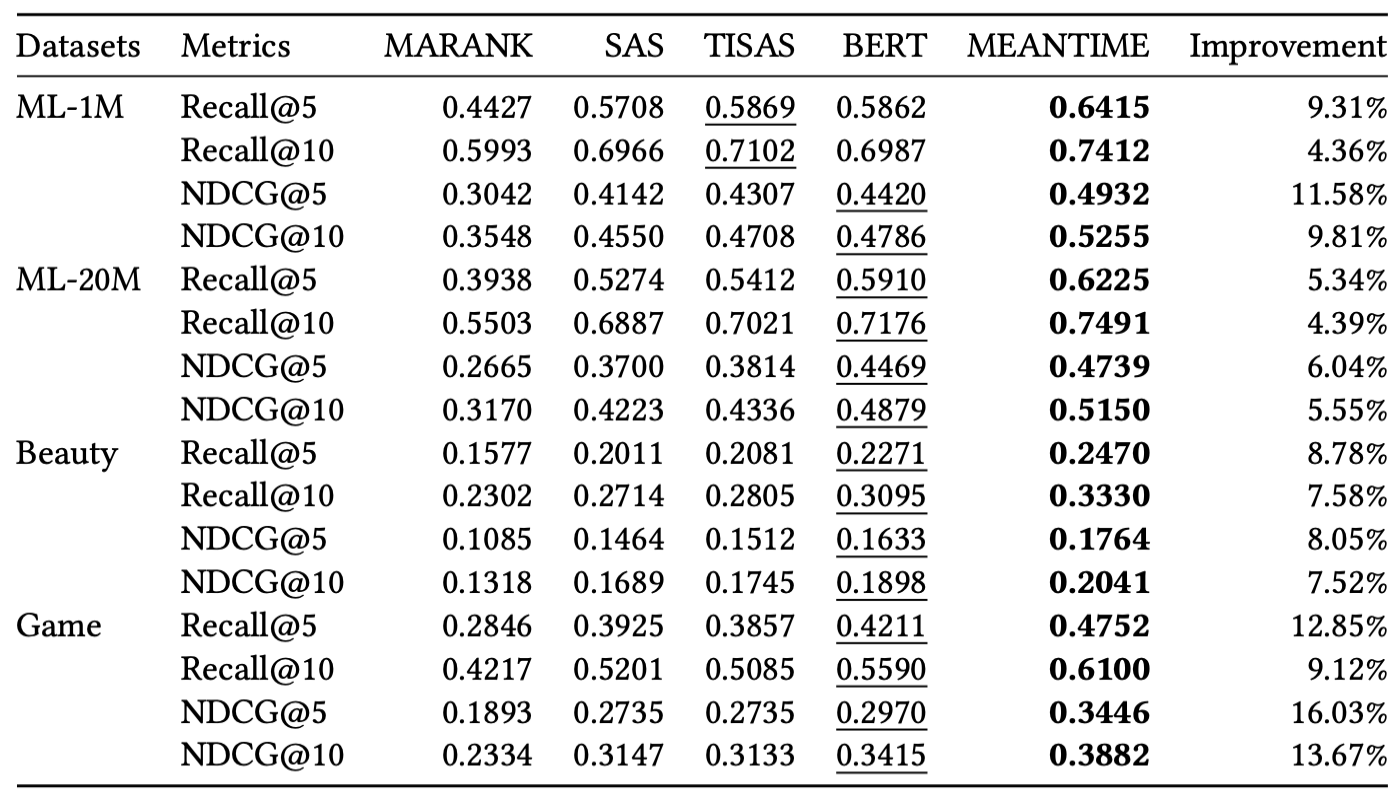
Recently, self-attention based models have achieved state-of-the-art performance in sequential recommendation task. Following the custom from language processing, most of these models rely on a simple positional embedding to exploit the sequential nature of the user's history. However, there are some limitations regarding the current approaches. First, sequential recommendation is different from language processing in that timestamp information is available. Previous models have not made good use of it to extract additional contextual information. Second, using a simple embedding scheme can lead to information bottleneck since the same embedding has to represent all possible contextual biases. Third, since previous models use the same positional embedding in each attention head, they can wastefully learn overlapping patterns. To address these limitations, we propose MEANTIME (MixturE of AtteNTIon mechanisms with Multi-temporal Embeddings) which employs multiple types of temporal embeddings designed to capture various patterns from the user's behavior sequence, and an attention structure that fully leverages such diversity. Experiments on real-world data show that our proposed method outperforms current state-of-the-art sequential recommendation methods, and we provide an extensive ablation study to analyze how the model gains from the diverse positional information.
PDF Abstract

 MovieLens
MovieLens
