MediumVC: Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
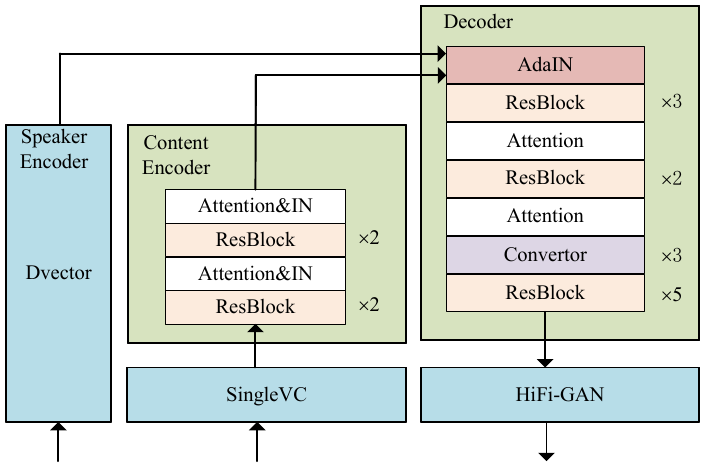
To realize any-to-any (A2A) voice conversion (VC), most methods are to perform symmetric self-supervised reconstruction tasks (Xi to Xi), which usually results in inefficient performances due to inadequate feature decoupling, especially for unseen speakers. We propose a two-stage reconstruction task (Xi to Yi to Xi) using synthetic specific-speaker speeches as intermedium features, where A2A VC is divided into two stages: any-to-one (A2O) and one-to-Any (O2A). In the A2O stage, we propose a new A2O method: SingleVC, by employing a noval data augment strategy(pitch-shifted and duration-remained, PSDR) to accomplish Xi to Yi. In the O2A stage, MediumVC is proposed based on pre-trained SingleVC to conduct Yi to Xi. Through such asymmetrical reconstruction tasks (Xi to Yi in SingleVC and Yi to Xi in MediumVC), the models are to capture robust disentangled features purposefully. Experiments indicate MediumVC can enhance the similarity of converted speeches while maintaining a high degree of naturalness.
PDF Abstract

 LibriSpeech
LibriSpeech
