Metadata Shaping: Natural Language Annotations for the Tail
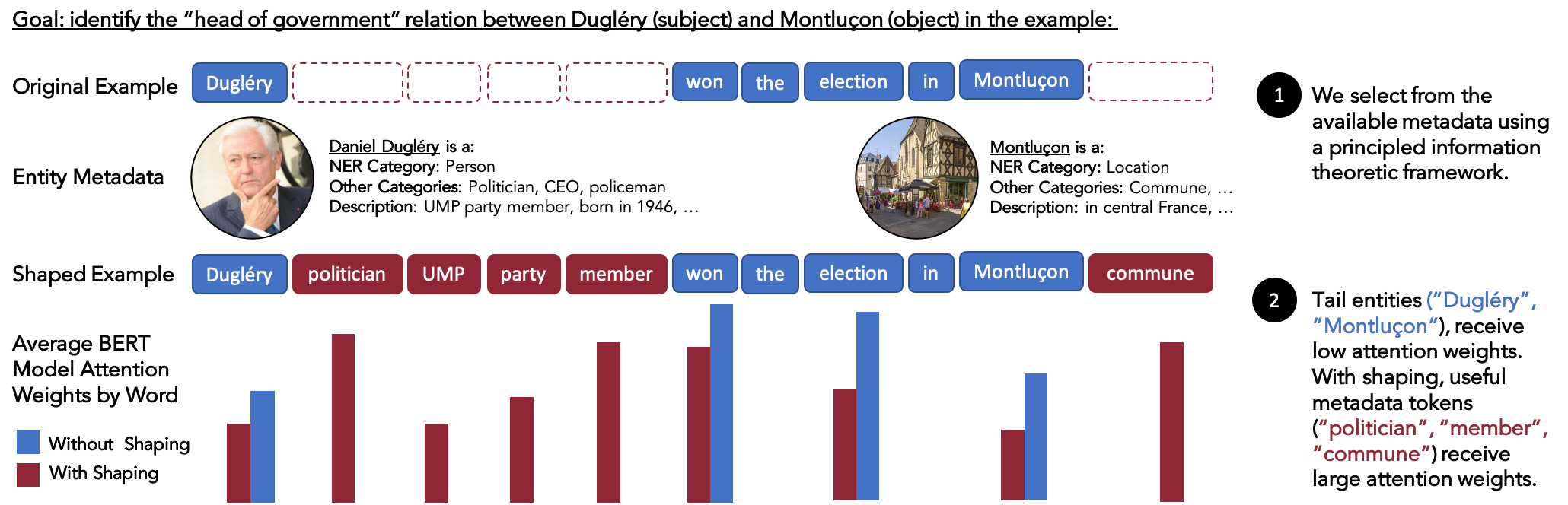
Language models (LMs) have made remarkable progress, but still struggle to generalize beyond the training data to rare linguistic patterns. Since rare entities and facts are prevalent in the queries users submit to popular applications such as search and personal assistant systems, improving the ability of LMs to reliably capture knowledge over rare entities is a pressing challenge studied in significant prior work. Noticing that existing approaches primarily modify the LM architecture or introduce auxiliary objectives to inject useful entity knowledge, we ask to what extent we could match the quality of these architectures using a base LM architecture, and only changing the data? We propose metadata shaping, a method in which readily available metadata, such as entity descriptions and categorical tags, are appended to examples based on information theoretic metrics. Intuitively, if metadata corresponding to popular entities overlap with metadata for rare entities, the LM may be able to better reason about the rare entities using patterns learned from similar popular entities. On standard entity-rich tasks (TACRED, FewRel, OpenEntity), with no changes to the LM whatsoever, metadata shaping exceeds the BERT-baseline by up to 5.3 F1 points, and achieves or competes with state-of-the-art results. We further show the improvements are up to 10x larger on examples containing tail versus popular entities.
PDF Abstract
 TACRED
TACRED
 FewRel
FewRel
 Open Entity
Open Entity
