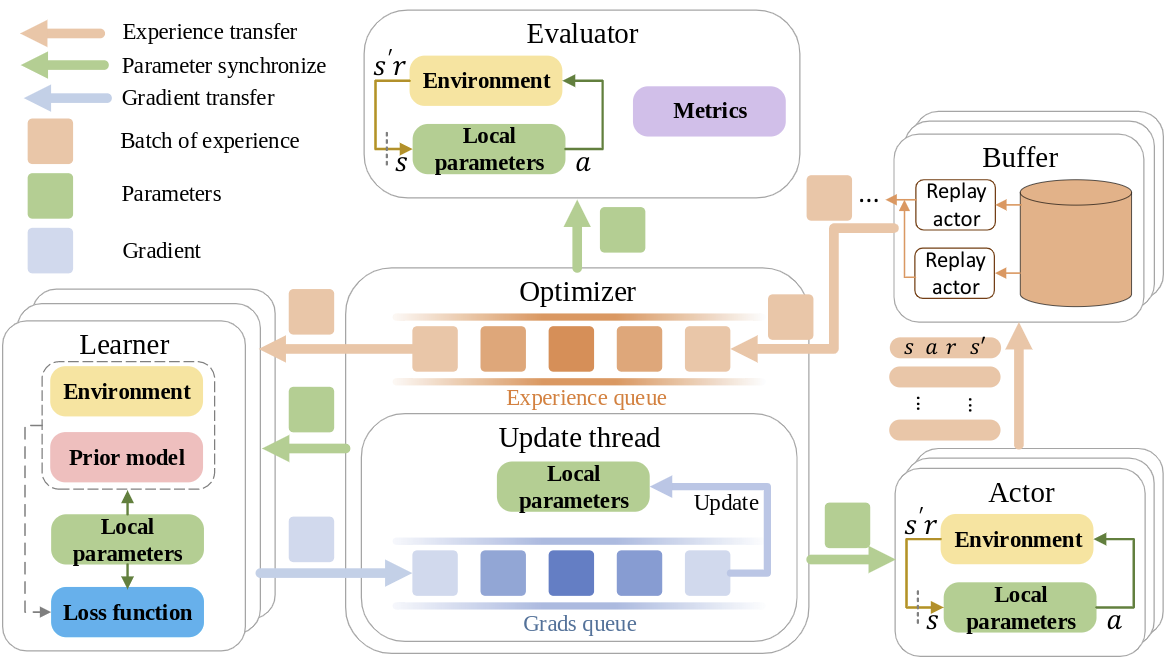
Mixed Policy Gradient: off-policy reinforcement learning driven jointly by data and model
Reinforcement learning (RL) shows great potential in sequential decision-making. At present, mainstream RL algorithms are data-driven, which usually yield better asymptotic performance but much slower convergence compared with model-driven methods. This paper proposes mixed policy gradient (MPG) algorithm, which fuses the empirical data and the transition model in policy gradient (PG) to accelerate convergence without performance degradation. Formally, MPG is constructed as a weighted average of the data-driven and model-driven PGs, where the former is the derivative of the learned Q-value function, and the latter is that of the model-predictive return. To guide the weight design, we analyze and compare the upper bound of each PG error. Relying on that, a rule-based method is employed to heuristically adjust the weights. In particular, to get a better PG, the weight of the data-driven PG is designed to grow along the learning process while the other to decrease. Simulation results show that the MPG method achieves the best asymptotic performance and convergence speed compared with other baseline algorithms.
PDF Abstract

