MMFace4D: A Large-Scale Multi-Modal 4D Face Dataset for Audio-Driven 3D Face Animation
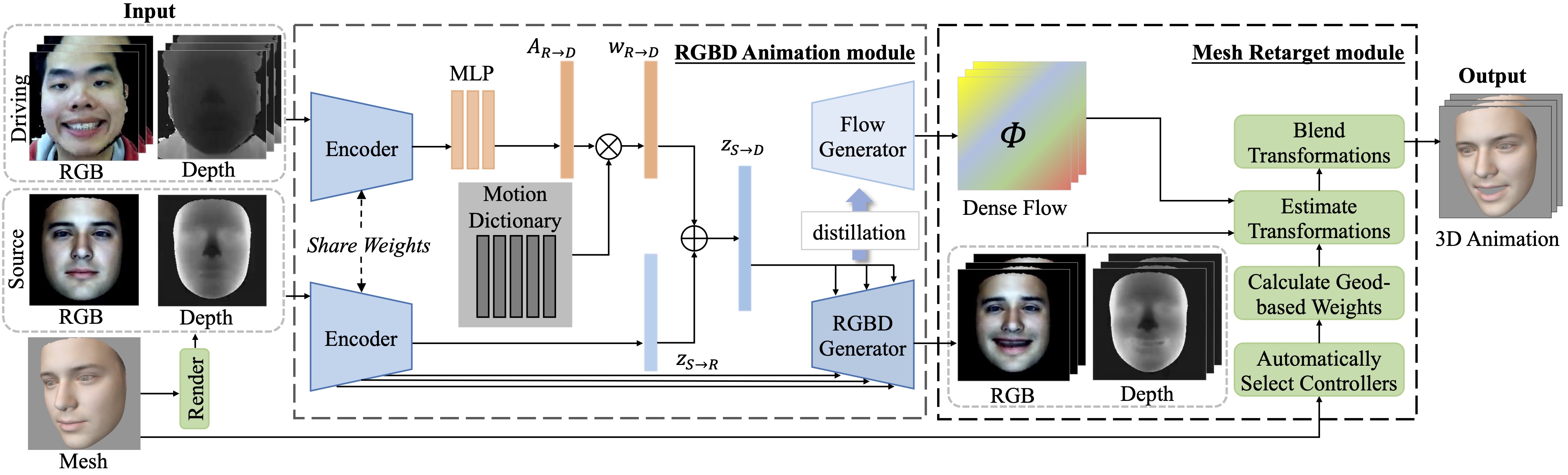
Audio-Driven Face Animation is an eagerly anticipated technique for applications such as VR/AR, games, and movie making. With the rapid development of 3D engines, there is an increasing demand for driving 3D faces with audio. However, currently available 3D face animation datasets are either scale-limited or quality-unsatisfied, which hampers further developments of audio-driven 3D face animation. To address this challenge, we propose MMFace4D, a large-scale multi-modal 4D (3D sequence) face dataset consisting of 431 identities, 35,904 sequences, and 3.9 million frames. MMFace4D exhibits two compelling characteristics: 1) a remarkably diverse set of subjects and corpus, encompassing actors spanning ages 15 to 68, and recorded sentences with durations ranging from 0.7 to 11.4 seconds. 2) It features synchronized audio and 3D mesh sequences with high-resolution face details. To capture the subtle nuances of 3D facial expressions, we leverage three synchronized RGBD cameras during the recording process. Upon MMFace4D, we construct a non-autoregressive framework for audio-driven 3D face animation. Our framework considers the regional and composite natures of facial animations, and surpasses contemporary state-of-the-art approaches both qualitatively and quantitatively. The code, model, and dataset will be publicly available.
PDF Abstract

 MEAD
MEAD
 VOCASET
VOCASET
