Modeling Moral Choices in Social Dilemmas with Multi-Agent Reinforcement Learning
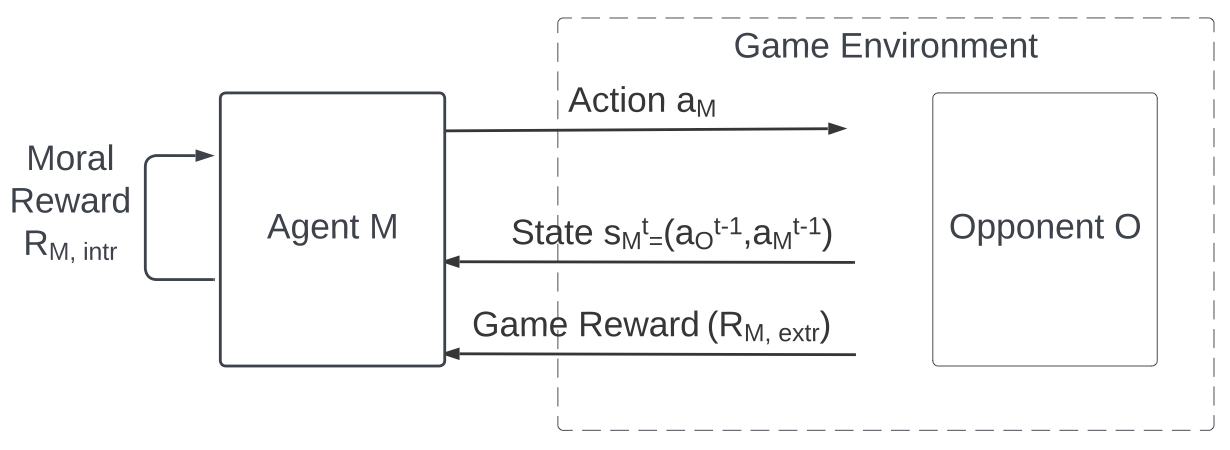
Practical uses of Artificial Intelligence (AI) in the real world have demonstrated the importance of embedding moral choices into intelligent agents. They have also highlighted that defining top-down ethical constraints on AI according to any one type of morality is extremely challenging and can pose risks. A bottom-up learning approach may be more appropriate for studying and developing ethical behavior in AI agents. In particular, we believe that an interesting and insightful starting point is the analysis of emergent behavior of Reinforcement Learning (RL) agents that act according to a predefined set of moral rewards in social dilemmas. In this work, we present a systematic analysis of the choices made by intrinsically-motivated RL agents whose rewards are based on moral theories. We aim to design reward structures that are simplified yet representative of a set of key ethical systems. Therefore, we first define moral reward functions that distinguish between consequence- and norm-based agents, between morality based on societal norms or internal virtues, and between single- and mixed-virtue (e.g., multi-objective) methodologies. Then, we evaluate our approach by modeling repeated dyadic interactions between learning moral agents in three iterated social dilemma games (Prisoner's Dilemma, Volunteer's Dilemma and Stag Hunt). We analyze the impact of different types of morality on the emergence of cooperation, defection or exploitation, and the corresponding social outcomes. Finally, we discuss the implications of these findings for the development of moral agents in artificial and mixed human-AI societies.
PDF Abstract
