Modeling Motion with Multi-Modal Features for Text-Based Video Segmentation
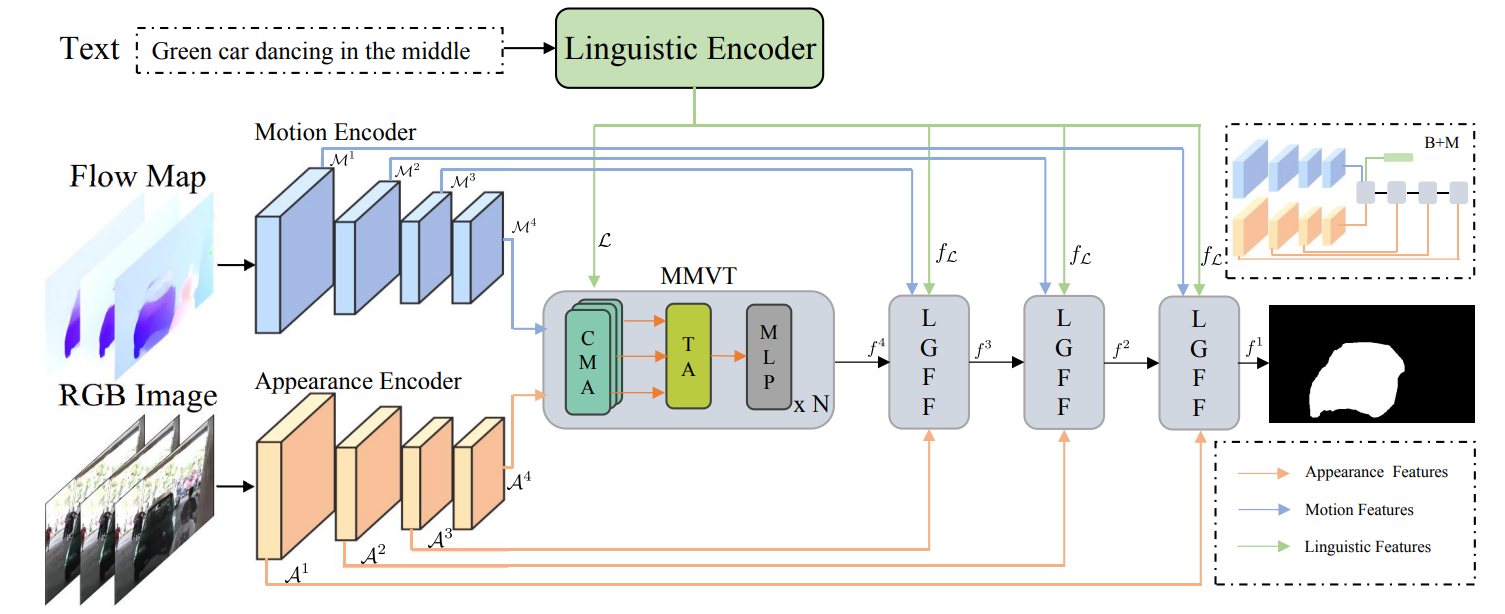
Text-based video segmentation aims to segment the target object in a video based on a describing sentence. Incorporating motion information from optical flow maps with appearance and linguistic modalities is crucial yet has been largely ignored by previous work. In this paper, we design a method to fuse and align appearance, motion, and linguistic features to achieve accurate segmentation. Specifically, we propose a multi-modal video transformer, which can fuse and aggregate multi-modal and temporal features between frames. Furthermore, we design a language-guided feature fusion module to progressively fuse appearance and motion features in each feature level with guidance from linguistic features. Finally, a multi-modal alignment loss is proposed to alleviate the semantic gap between features from different modalities. Extensive experiments on A2D Sentences and J-HMDB Sentences verify the performance and the generalization ability of our method compared to the state-of-the-art methods.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract



 JHMDB
JHMDB
 A2D
A2D
 A2D Sentences
A2D Sentences

