Modeling Visual Context is Key to Augmenting Object Detection Datasets
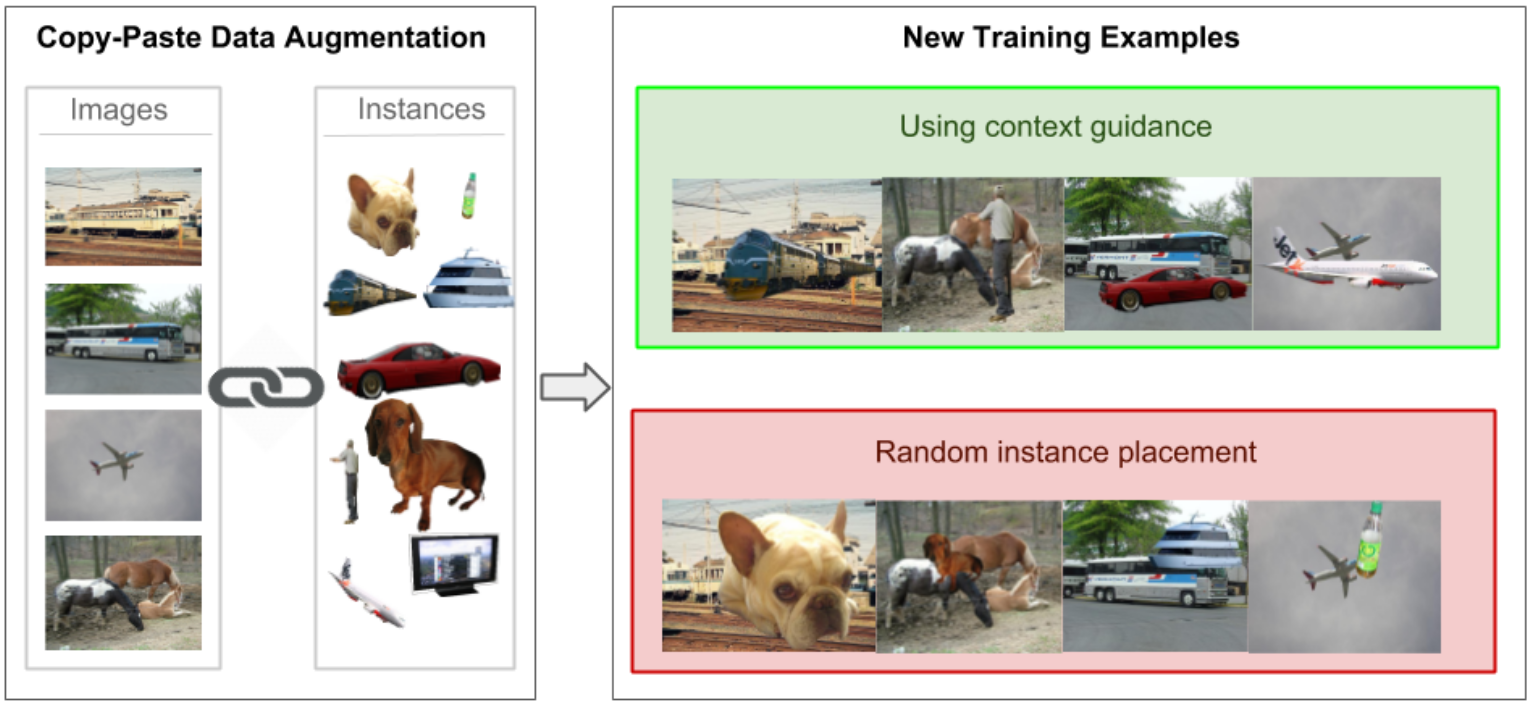
Performing data augmentation for learning deep neural networks is well known to be important for training visual recognition systems. By artificially increasing the number of training examples, it helps reducing overfitting and improves generalization. For object detection, classical approaches for data augmentation consist of generating images obtained by basic geometrical transformations and color changes of original training images. In this work, we go one step further and leverage segmentation annotations to increase the number of object instances present on training data. For this approach to be successful, we show that modeling appropriately the visual context surrounding objects is crucial to place them in the right environment. Otherwise, we show that the previous strategy actually hurts. With our context model, we achieve significant mean average precision improvements when few labeled examples are available on the VOC'12 benchmark.
PDF Abstract ECCV 2018 PDF ECCV 2018 Abstract



 MS COCO
MS COCO
