Modular Deep Reinforcement Learning with Temporal Logic Specifications
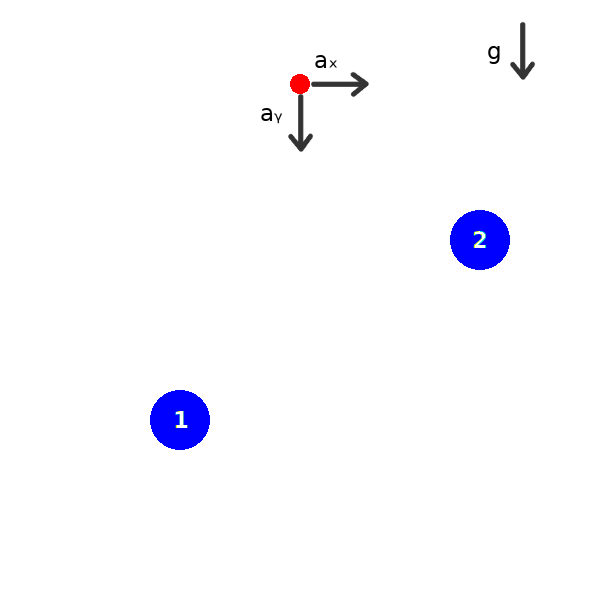
We propose an actor-critic, model-free, and online Reinforcement Learning (RL) framework for continuous-state continuous-action Markov Decision Processes (MDPs) when the reward is highly sparse but encompasses a high-level temporal structure. We represent this temporal structure by a finite-state machine and construct an on-the-fly synchronised product with the MDP and the finite machine. The temporal structure acts as a guide for the RL agent within the product, where a modular Deep Deterministic Policy Gradient (DDPG) architecture is proposed to generate a low-level control policy. We evaluate our framework in a Mars rover experiment and we present the success rate of the synthesised policy.
PDF Abstract

Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
