Monocular 3D Multi-Person Pose Estimation by Integrating Top-Down and Bottom-Up Networks
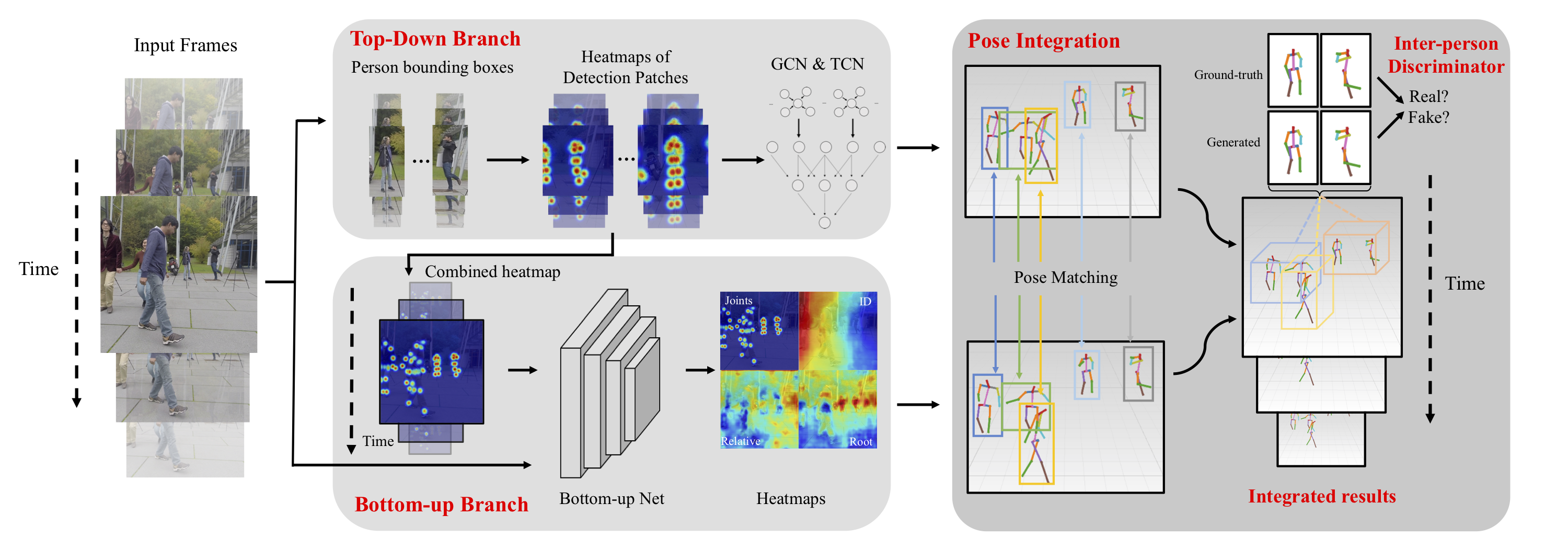
In monocular video 3D multi-person pose estimation, inter-person occlusion and close interactions can cause human detection to be erroneous and human-joints grouping to be unreliable. Existing top-down methods rely on human detection and thus suffer from these problems. Existing bottom-up methods do not use human detection, but they process all persons at once at the same scale, causing them to be sensitive to multiple-persons scale variations. To address these challenges, we propose the integration of top-down and bottom-up approaches to exploit their strengths. Our top-down network estimates human joints from all persons instead of one in an image patch, making it robust to possible erroneous bounding boxes. Our bottom-up network incorporates human-detection based normalized heatmaps, allowing the network to be more robust in handling scale variations. Finally, the estimated 3D poses from the top-down and bottom-up networks are fed into our integration network for final 3D poses. Besides the integration of top-down and bottom-up networks, unlike existing pose discriminators that are designed solely for single person, and consequently cannot assess natural inter-person interactions, we propose a two-person pose discriminator that enforces natural two-person interactions. Lastly, we also apply a semi-supervised method to overcome the 3D ground-truth data scarcity. Our quantitative and qualitative evaluations show the effectiveness of our method compared to the state-of-the-art baselines.
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract






 MS COCO
MS COCO
 Human3.6M
Human3.6M
 3DPW
3DPW
 MuPoTS-3D
MuPoTS-3D
 JTA
JTA

