MPNet: Masked and Permuted Pre-training for Language Understanding
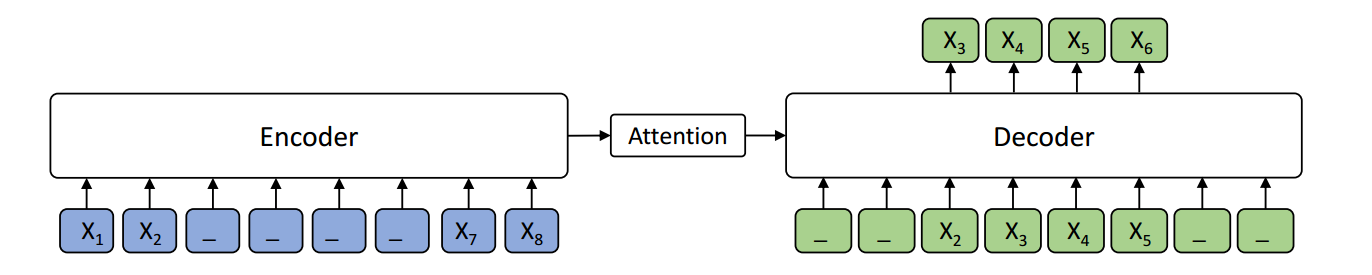
BERT adopts masked language modeling (MLM) for pre-training and is one of the most successful pre-training models. Since BERT neglects dependency among predicted tokens, XLNet introduces permuted language modeling (PLM) for pre-training to address this problem. However, XLNet does not leverage the full position information of a sentence and thus suffers from position discrepancy between pre-training and fine-tuning. In this paper, we propose MPNet, a novel pre-training method that inherits the advantages of BERT and XLNet and avoids their limitations. MPNet leverages the dependency among predicted tokens through permuted language modeling (vs. MLM in BERT), and takes auxiliary position information as input to make the model see a full sentence and thus reducing the position discrepancy (vs. PLM in XLNet). We pre-train MPNet on a large-scale dataset (over 160GB text corpora) and fine-tune on a variety of down-streaming tasks (GLUE, SQuAD, etc). Experimental results show that MPNet outperforms MLM and PLM by a large margin, and achieves better results on these tasks compared with previous state-of-the-art pre-trained methods (e.g., BERT, XLNet, RoBERTa) under the same model setting. The code and the pre-trained models are available at: https://github.com/microsoft/MPNet.
PDF Abstract NeurIPS 2020 PDF NeurIPS 2020 AbstractCode




 GLUE
GLUE
 SST
SST
 SQuAD
SQuAD
 MultiNLI
MultiNLI
 IMDb Movie Reviews
IMDb Movie Reviews
 QNLI
QNLI
 MRPC
MRPC
 CoLA
CoLA
 RACE
RACE
 OCW
OCW
Results from the Paper
 Ranked #16 on
Only Connect Walls Dataset Task 1 (Grouping)
on OCW
(using extra training data)
Ranked #16 on
Only Connect Walls Dataset Task 1 (Grouping)
on OCW
(using extra training data)
| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Only Connect Walls Dataset Task 1 (Grouping) | OCW | all-mpnet (BASE) | Wasserstein Distance (WD) | 86.3 ± .4 | # 16 | ||
| # Correct Groups | 50 ± 4 | # 18 | |||||
| Fowlkes Mallows Score (FMS) | 29.4 ± .3 | # 17 | |||||
| Adjusted Rand Index (ARI) | 11.7 ± .4 | # 17 | |||||
| Adjusted Mutual Information (AMI) | 14.3 ± .5 | # 17 | |||||
| # Solved Walls | 0 ± 0 | # 10 |
