Multi-Compound Transformer for Accurate Biomedical Image Segmentation
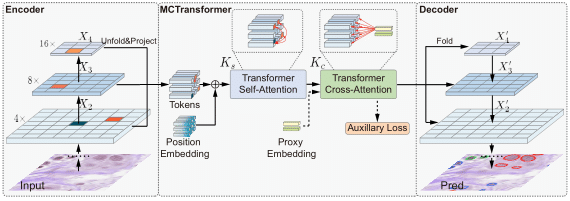
The recent vision transformer(i.e.for image classification) learns non-local attentive interaction of different patch tokens. However, prior arts miss learning the cross-scale dependencies of different pixels, the semantic correspondence of different labels, and the consistency of the feature representations and semantic embeddings, which are critical for biomedical segmentation. In this paper, we tackle the above issues by proposing a unified transformer network, termed Multi-Compound Transformer (MCTrans), which incorporates rich feature learning and semantic structure mining into a unified framework. Specifically, MCTrans embeds the multi-scale convolutional features as a sequence of tokens and performs intra- and inter-scale self-attention, rather than single-scale attention in previous works. In addition, a learnable proxy embedding is also introduced to model semantic relationship and feature enhancement by using self-attention and cross-attention, respectively. MCTrans can be easily plugged into a UNet-like network and attains a significant improvement over the state-of-the-art methods in biomedical image segmentation in six standard benchmarks. For example, MCTrans outperforms UNet by 3.64%, 3.71%, 4.34%, 2.8%, 1.88%, 1.57% in Pannuke, CVC-Clinic, CVC-Colon, Etis, Kavirs, ISIC2018 dataset, respectively. Code is available at https://github.com/JiYuanFeng/MCTrans.
PDF Abstract



