Multi-label Classification with Partial Annotations using Class-aware Selective Loss
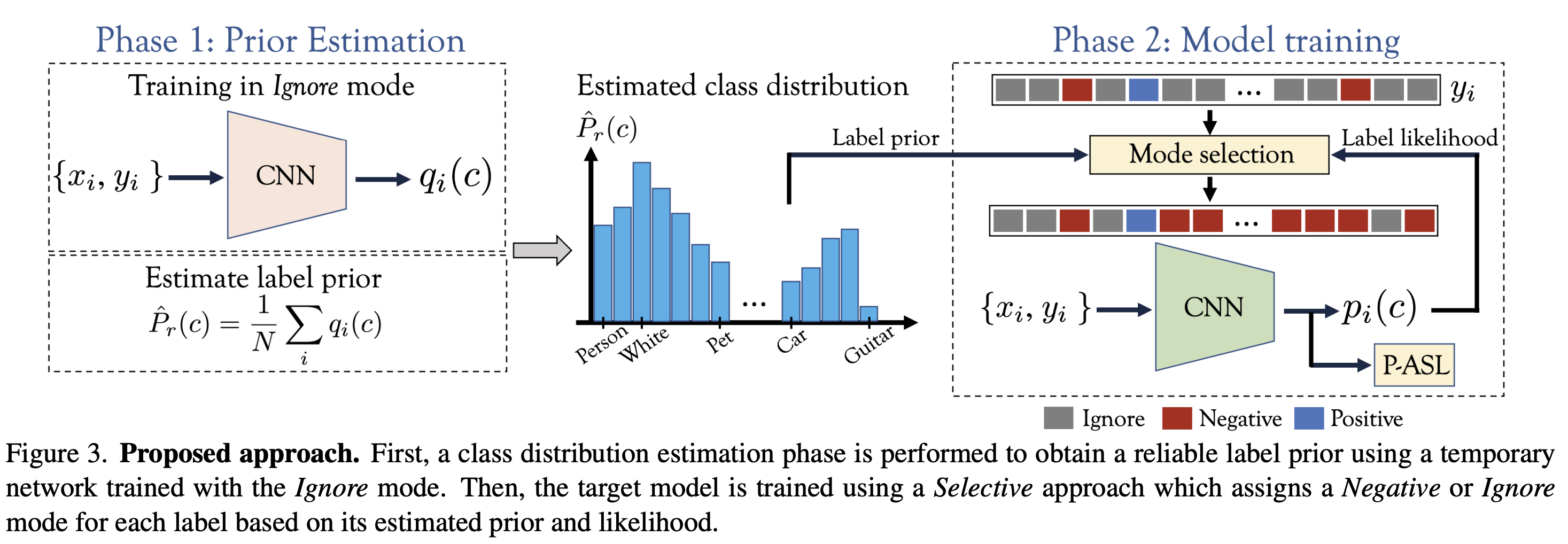
Large-scale multi-label classification datasets are commonly, and perhaps inevitably, partially annotated. That is, only a small subset of labels are annotated per sample. Different methods for handling the missing labels induce different properties on the model and impact its accuracy. In this work, we analyze the partial labeling problem, then propose a solution based on two key ideas. First, un-annotated labels should be treated selectively according to two probability quantities: the class distribution in the overall dataset and the specific label likelihood for a given data sample. We propose to estimate the class distribution using a dedicated temporary model, and we show its improved efficiency over a naive estimation computed using the dataset's partial annotations. Second, during the training of the target model, we emphasize the contribution of annotated labels over originally un-annotated labels by using a dedicated asymmetric loss. With our novel approach, we achieve state-of-the-art results on OpenImages dataset (e.g. reaching 87.3 mAP on V6). In addition, experiments conducted on LVIS and simulated-COCO demonstrate the effectiveness of our approach. Code is available at https://github.com/Alibaba-MIIL/PartialLabelingCSL.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract

 MS COCO
MS COCO
 LVIS
LVIS

