Multi-modal Dense Video Captioning
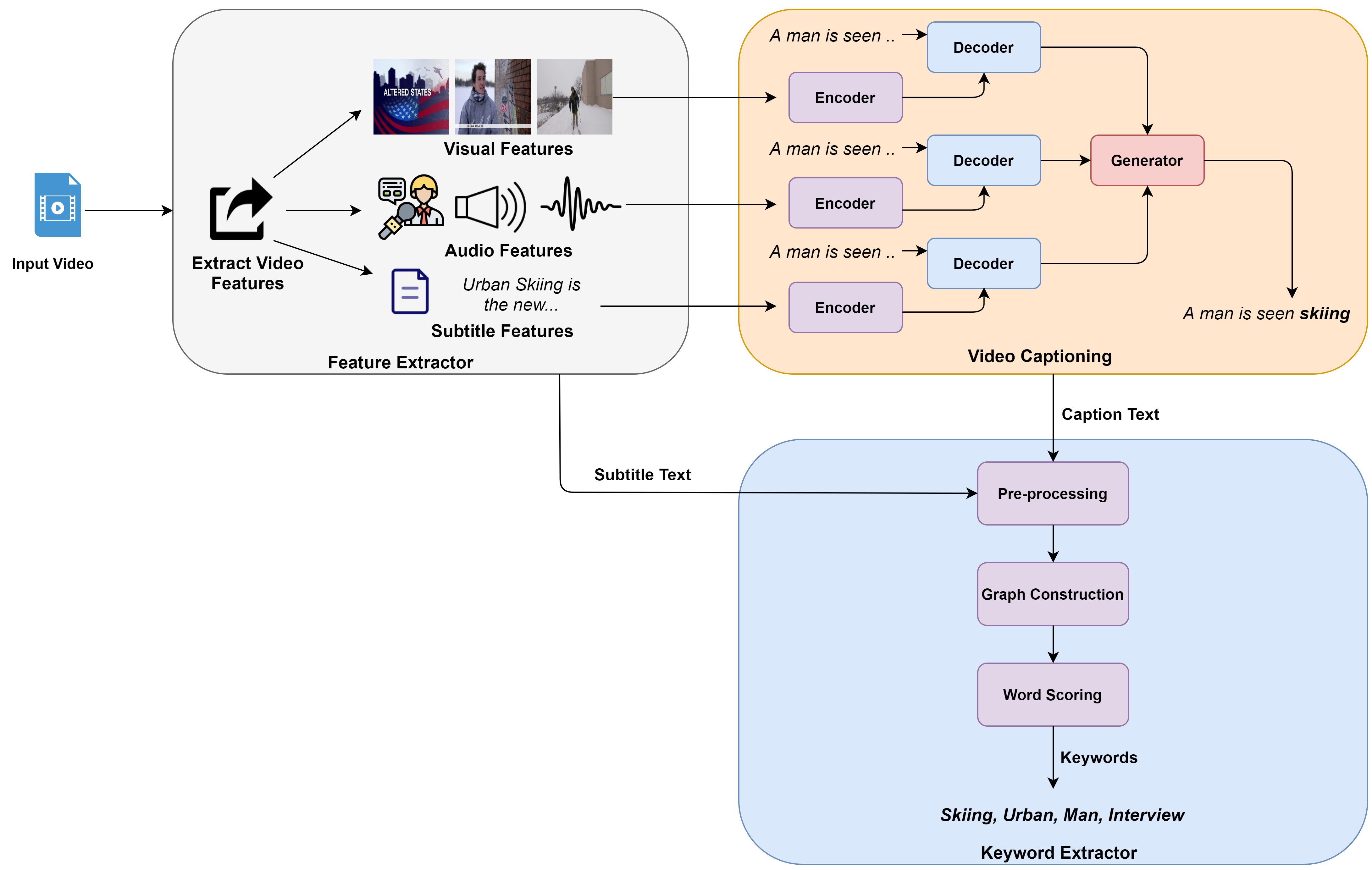
Dense video captioning is a task of localizing interesting events from an untrimmed video and producing textual description (captions) for each localized event. Most of the previous works in dense video captioning are solely based on visual information and completely ignore the audio track. However, audio, and speech, in particular, are vital cues for a human observer in understanding an environment. In this paper, we present a new dense video captioning approach that is able to utilize any number of modalities for event description. Specifically, we show how audio and speech modalities may improve a dense video captioning model. We apply automatic speech recognition (ASR) system to obtain a temporally aligned textual description of the speech (similar to subtitles) and treat it as a separate input alongside video frames and the corresponding audio track. We formulate the captioning task as a machine translation problem and utilize recently proposed Transformer architecture to convert multi-modal input data into textual descriptions. We demonstrate the performance of our model on ActivityNet Captions dataset. The ablation studies indicate a considerable contribution from audio and speech components suggesting that these modalities contain substantial complementary information to video frames. Furthermore, we provide an in-depth analysis of the ActivityNet Caption results by leveraging the category tags obtained from original YouTube videos. Code is publicly available: github.com/v-iashin/MDVC
PDF Abstract
 Colab
Colab


 ActivityNet Captions
ActivityNet Captions

