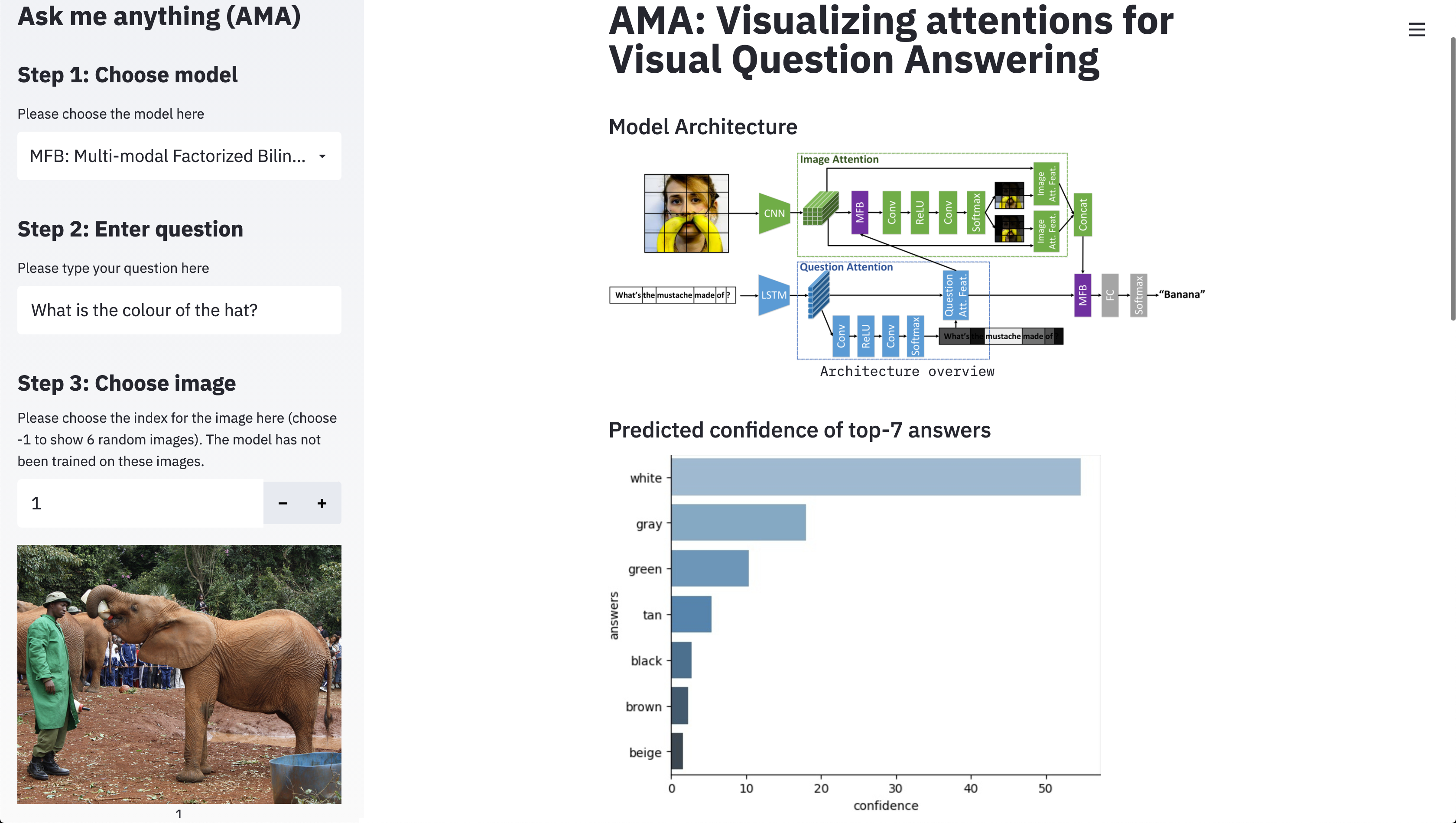
Multi-modal Factorized Bilinear Pooling with Co-Attention Learning for Visual Question Answering
Visual question answering (VQA) is challenging because it requires a simultaneous understanding of both the visual content of images and the textual content of questions. The approaches used to represent the images and questions in a fine-grained manner and questions and to fuse these multi-modal features play key roles in performance. Bilinear pooling based models have been shown to outperform traditional linear models for VQA, but their high-dimensional representations and high computational complexity may seriously limit their applicability in practice. For multi-modal feature fusion, here we develop a Multi-modal Factorized Bilinear (MFB) pooling approach to efficiently and effectively combine multi-modal features, which results in superior performance for VQA compared with other bilinear pooling approaches. For fine-grained image and question representation, we develop a co-attention mechanism using an end-to-end deep network architecture to jointly learn both the image and question attentions. Combining the proposed MFB approach with co-attention learning in a new network architecture provides a unified model for VQA. Our experimental results demonstrate that the single MFB with co-attention model achieves new state-of-the-art performance on the real-world VQA dataset. Code available at https://github.com/yuzcccc/mfb.
PDF Abstract ICCV 2017 PDF ICCV 2017 Abstract




 Visual Question Answering
Visual Question Answering
 Visual Genome
Visual Genome
