Multi-Modal Self-Supervised Learning for Recommendation
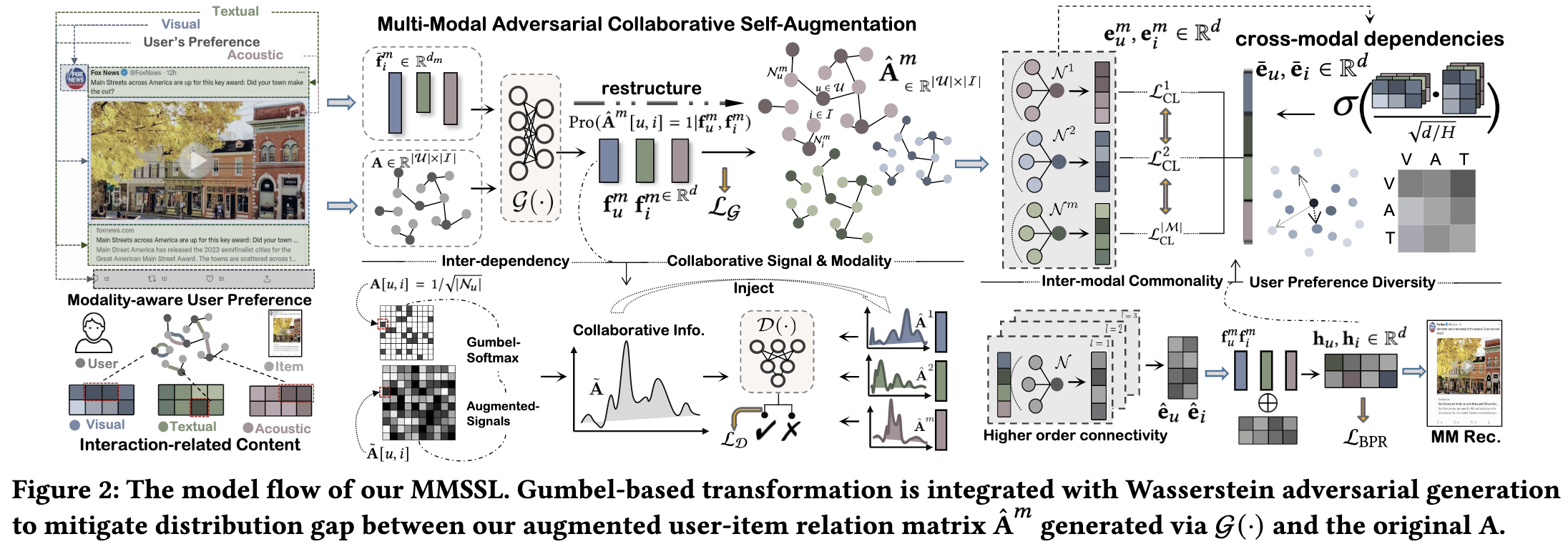
The online emergence of multi-modal sharing platforms (eg, TikTok, Youtube) is powering personalized recommender systems to incorporate various modalities (eg, visual, textual and acoustic) into the latent user representations. While existing works on multi-modal recommendation exploit multimedia content features in enhancing item embeddings, their model representation capability is limited by heavy label reliance and weak robustness on sparse user behavior data. Inspired by the recent progress of self-supervised learning in alleviating label scarcity issue, we explore deriving self-supervision signals with effectively learning of modality-aware user preference and cross-modal dependencies. To this end, we propose a new Multi-Modal Self-Supervised Learning (MMSSL) method which tackles two key challenges. Specifically, to characterize the inter-dependency between the user-item collaborative view and item multi-modal semantic view, we design a modality-aware interactive structure learning paradigm via adversarial perturbations for data augmentation. In addition, to capture the effects that user's modality-aware interaction pattern would interweave with each other, a cross-modal contrastive learning approach is introduced to jointly preserve the inter-modal semantic commonality and user preference diversity. Experiments on real-world datasets verify the superiority of our method in offering great potential for multimedia recommendation over various state-of-the-art baselines. The implementation is released at: https://github.com/HKUDS/MMSSL.
PDF Abstract





