Multi-view Deep Subspace Clustering Networks
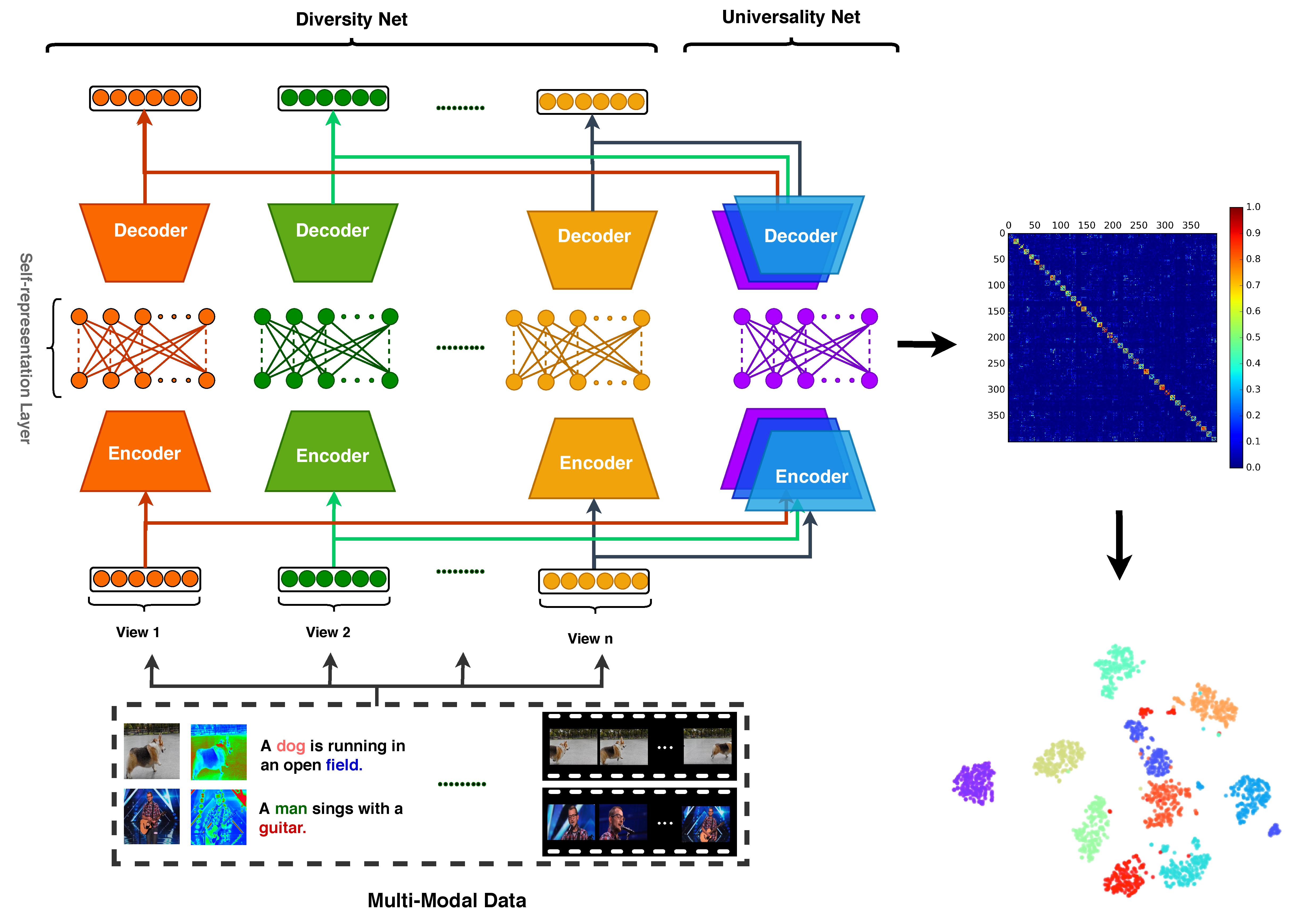
Multi-view subspace clustering aims to discover the inherent structure of data by fusing multiple views of complementary information. Most existing methods first extract multiple types of handcrafted features and then learn a joint affinity matrix for clustering. The disadvantage of this approach lies in two aspects: 1) multi-view relations are not embedded into feature learning, and 2) the end-to-end learning manner of deep learning is not suitable for multi-view clustering. Even when deep features have been extracted, it is a nontrivial problem to choose a proper backbone for clustering on different datasets. To address these issues, we propose the Multi-view Deep Subspace Clustering Networks (MvDSCN), which learns a multi-view self-representation matrix in an end-to-end manner. The MvDSCN consists of two sub-networks, \ie, a diversity network (Dnet) and a universality network (Unet). A latent space is built using deep convolutional autoencoders, and a self-representation matrix is learned in the latent space using a fully connected layer. Dnet learns view-specific self-representation matrices, whereas Unet learns a common self-representation matrix for all views. To exploit the complementarity of multi-view representations, the Hilbert--Schmidt independence criterion (HSIC) is introduced as a diversity regularizer that captures the nonlinear, high-order inter-view relations. Because different views share the same label space, the self-representation matrices of each view are aligned to the common one by universality regularization. The MvDSCN also unifies multiple backbones to boost clustering performance and avoid the need for model selection. Experiments demonstrate the superiority of the MvDSCN.
PDF Abstract


 ImageNet
ImageNet
 CUB-200-2011
CUB-200-2011
 ORL
ORL

