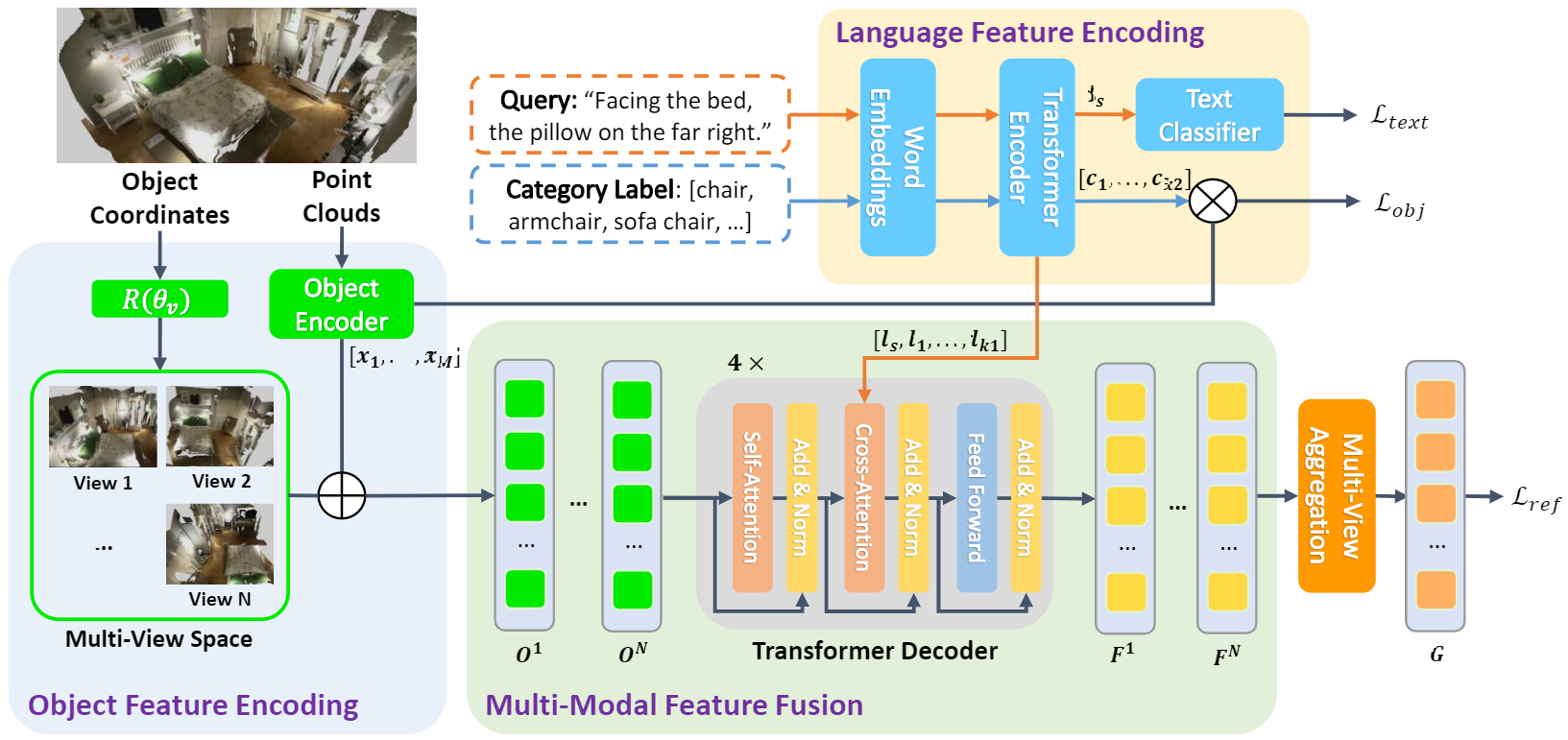
Multi-View Transformer for 3D Visual Grounding
The 3D visual grounding task aims to ground a natural language description to the targeted object in a 3D scene, which is usually represented in 3D point clouds. Previous works studied visual grounding under specific views. The vision-language correspondence learned by this way can easily fail once the view changes. In this paper, we propose a Multi-View Transformer (MVT) for 3D visual grounding. We project the 3D scene to a multi-view space, in which the position information of the 3D scene under different views are modeled simultaneously and aggregated together. The multi-view space enables the network to learn a more robust multi-modal representation for 3D visual grounding and eliminates the dependence on specific views. Extensive experiments show that our approach significantly outperforms all state-of-the-art methods. Specifically, on Nr3D and Sr3D datasets, our method outperforms the best competitor by 11.2% and 7.1% and even surpasses recent work with extra 2D assistance by 5.9% and 6.6%. Our code is available at https://github.com/sega-hsj/MVT-3DVG.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract

 ScanNet
ScanNet
 COCO Captions
COCO Captions
