Multilingual ontology matching based on Wiktionary data accessible via SPARQL endpoint
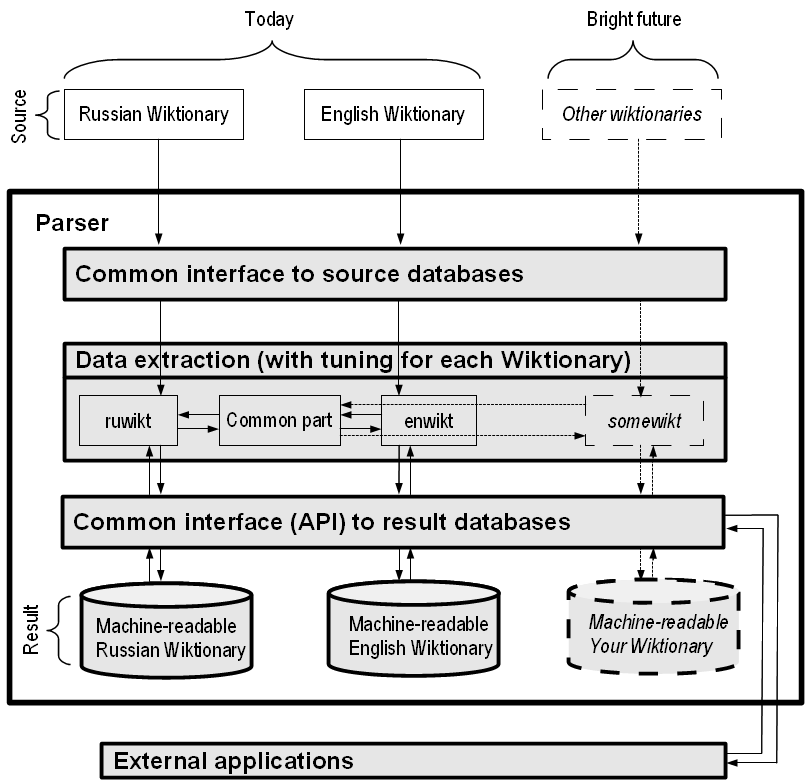
Interoperability is a feature required by the Semantic Web. It is provided by the ontology matching methods and algorithms. But now ontologies are presented not only in English, but in other languages as well. It is important to use an automatic translation for obtaining correct matching pairs in multilingual ontology matching. The translation into many languages could be based on the Google Translate API, the Wiktionary database, etc. From the point of view of the balance of presence of many languages, of manually crafted translations, of a huge size of a dictionary, the most promising resource is the Wiktionary. It is a collaborative project working on the same principles as the Wikipedia. The parser of the Wiktionary was developed and the machine-readable dictionary was designed. The data of the machine-readable Wiktionary are stored in a relational database, but with the help of D2R server the database is presented as an RDF store. Thus, it is possible to get lexicographic information (definitions, translations, synonyms) from web service using SPARQL requests. In the case study, the problem entity is a task of multilingual ontology matching based on Wiktionary data accessible via SPARQL endpoint. Ontology matching results obtained using Wiktionary were compared with results based on Google Translate API.
PDF Abstract
