Multimodal Multi-Head Convolutional Attention with Various Kernel Sizes for Medical Image Super-Resolution
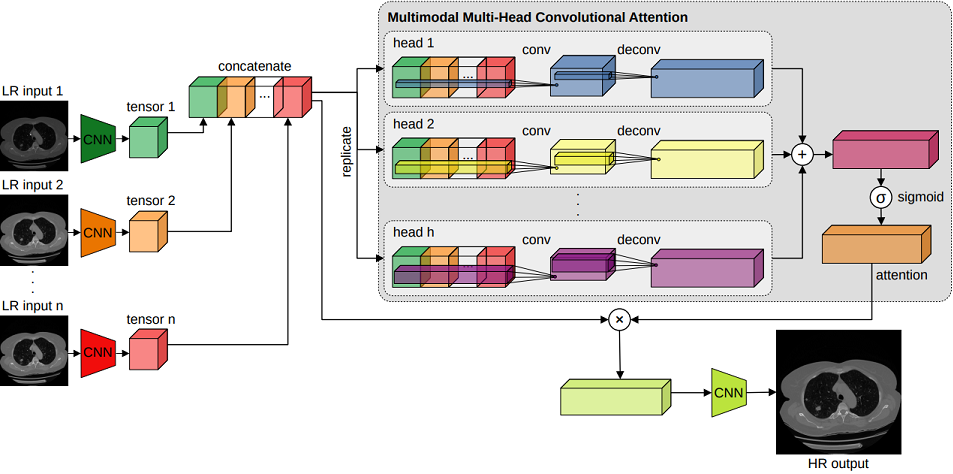
Super-resolving medical images can help physicians in providing more accurate diagnostics. In many situations, computed tomography (CT) or magnetic resonance imaging (MRI) techniques capture several scans (modes) during a single investigation, which can jointly be used (in a multimodal fashion) to further boost the quality of super-resolution results. To this end, we propose a novel multimodal multi-head convolutional attention module to super-resolve CT and MRI scans. Our attention module uses the convolution operation to perform joint spatial-channel attention on multiple concatenated input tensors, where the kernel (receptive field) size controls the reduction rate of the spatial attention, and the number of convolutional filters controls the reduction rate of the channel attention, respectively. We introduce multiple attention heads, each head having a distinct receptive field size corresponding to a particular reduction rate for the spatial attention. We integrate our multimodal multi-head convolutional attention (MMHCA) into two deep neural architectures for super-resolution and conduct experiments on three data sets. Our empirical results show the superiority of our attention module over the state-of-the-art attention mechanisms used in super-resolution. Moreover, we conduct an ablation study to assess the impact of the components involved in our attention module, e.g. the number of inputs or the number of heads. Our code is freely available at https://github.com/lilygeorgescu/MHCA.
PDF Abstract



 IXI
IXI

