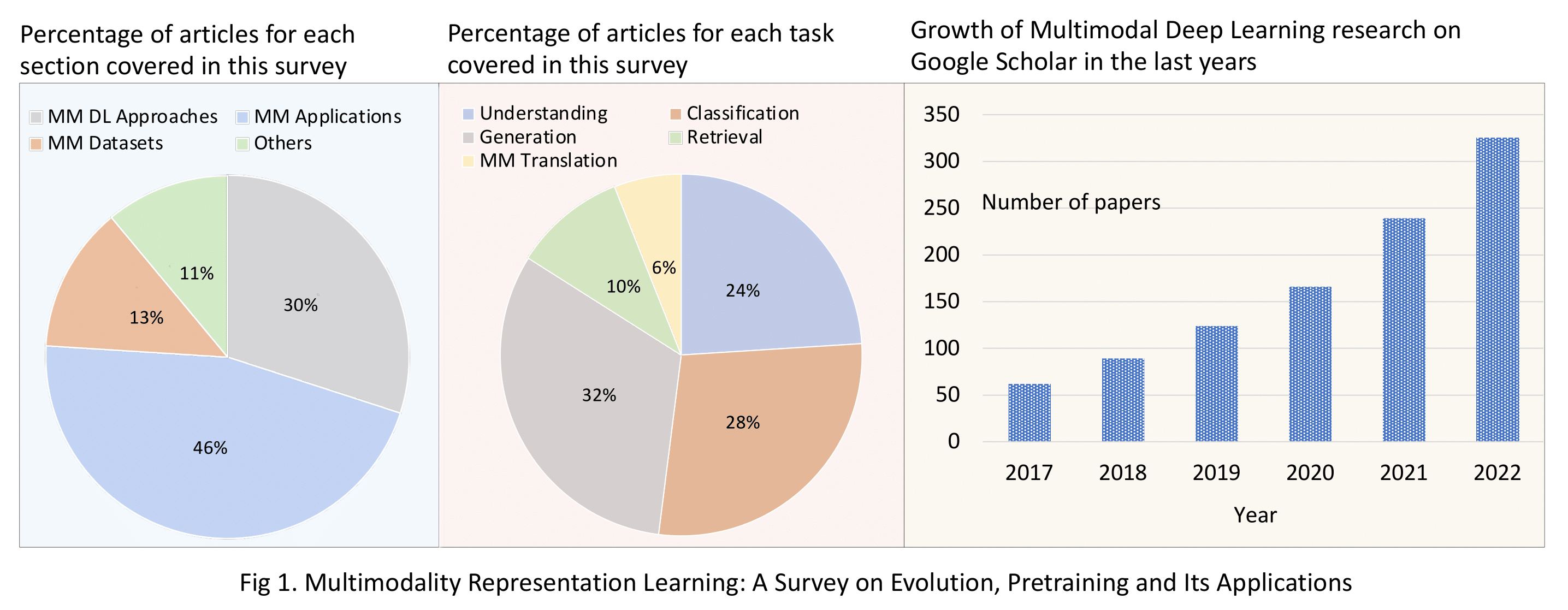
Multimodality Representation Learning: A Survey on Evolution, Pretraining and Its Applications
Multimodality Representation Learning, as a technique of learning to embed information from different modalities and their correlations, has achieved remarkable success on a variety of applications, such as Visual Question Answering (VQA), Natural Language for Visual Reasoning (NLVR), and Vision Language Retrieval (VLR). Among these applications, cross-modal interaction and complementary information from different modalities are crucial for advanced models to perform any multimodal task, e.g., understand, recognize, retrieve, or generate optimally. Researchers have proposed diverse methods to address these tasks. The different variants of transformer-based architectures performed extraordinarily on multiple modalities. This survey presents the comprehensive literature on the evolution and enhancement of deep learning multimodal architectures to deal with textual, visual and audio features for diverse cross-modal and modern multimodal tasks. This study summarizes the (i) recent task-specific deep learning methodologies, (ii) the pretraining types and multimodal pretraining objectives, (iii) from state-of-the-art pretrained multimodal approaches to unifying architectures, and (iv) multimodal task categories and possible future improvements that can be devised for better multimodal learning. Moreover, we prepare a dataset section for new researchers that covers most of the benchmarks for pretraining and finetuning. Finally, major challenges, gaps, and potential research topics are explored. A constantly-updated paperlist related to our survey is maintained at https://github.com/marslanm/multimodality-representation-learning.
PDF Abstract



 MS COCO
MS COCO
 CUB-200-2011
CUB-200-2011
 Visual Question Answering
Visual Question Answering
 nuScenes
nuScenes
 Visual Genome
Visual Genome
 Oxford 102 Flower
Oxford 102 Flower
 MIMIC-III
MIMIC-III
 MSR-VTT
MSR-VTT
 Conceptual Captions
Conceptual Captions
 YFCC100M
YFCC100M
 VCR
VCR
 CMU-MOSEI
CMU-MOSEI
 NoCaps
NoCaps
 FUNSD
FUNSD
 TGIF-QA
TGIF-QA
 SROIE
SROIE
 How2
How2
 Multimodal Opinionlevel Sentiment Intensity
Multimodal Opinionlevel Sentiment Intensity
 EQA
EQA
 TDIUC
TDIUC
 VideoNavQA
VideoNavQA
