Music Source Separation with Generative Flow
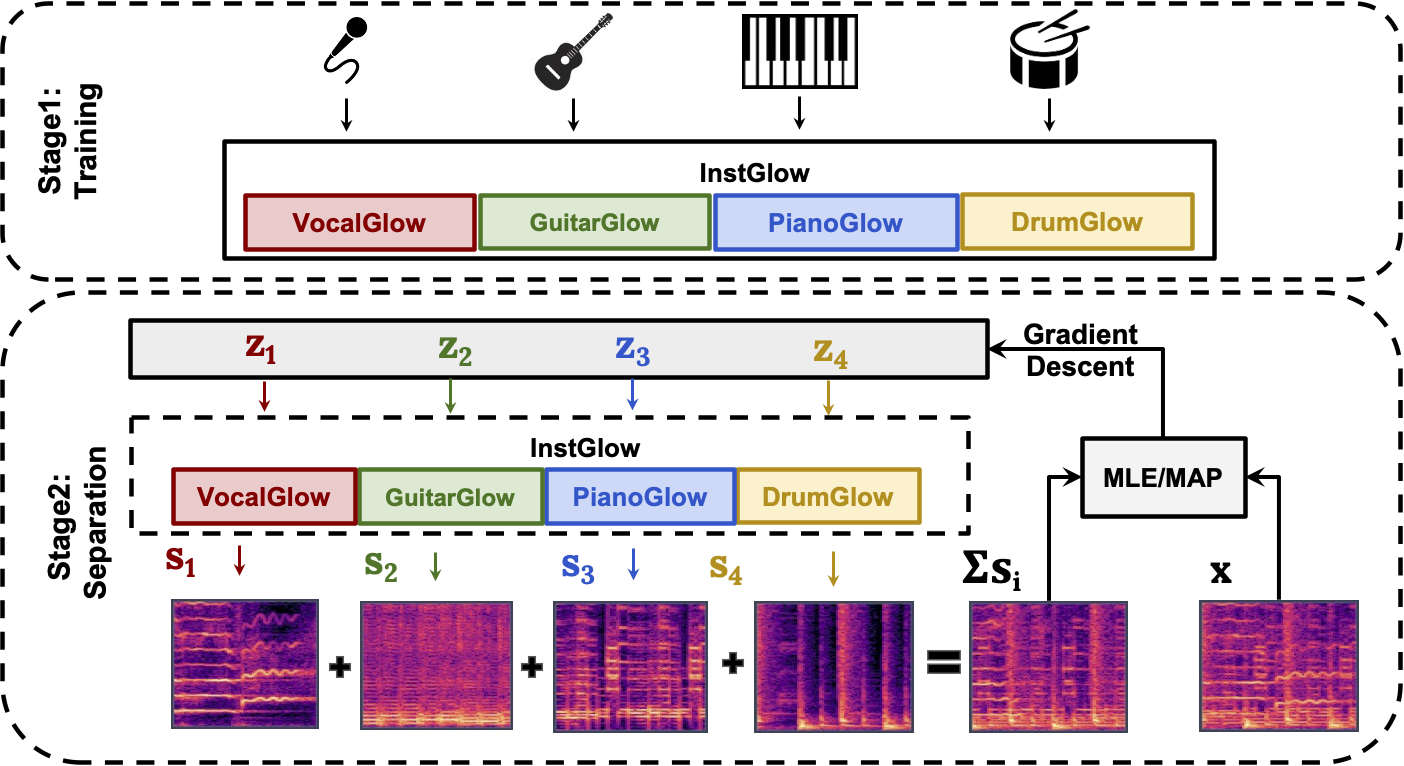
Fully-supervised models for source separation are trained on parallel mixture-source data and are currently state-of-the-art. However, such parallel data is often difficult to obtain, and it is cumbersome to adapt trained models to mixtures with new sources. Source-only supervised models, in contrast, only require individual source data for training. In this paper, we first leverage flow-based generators to train individual music source priors and then use these models, along with likelihood-based objectives, to separate music mixtures. We show that in singing voice separation and music separation tasks, our proposed method is competitive with a fully-supervised approach. We also demonstrate that we can flexibly add new types of sources, whereas fully-supervised approaches would require retraining of the entire model.
PDF Abstract

 MUSDB18
MUSDB18
 Slakh2100
Slakh2100
