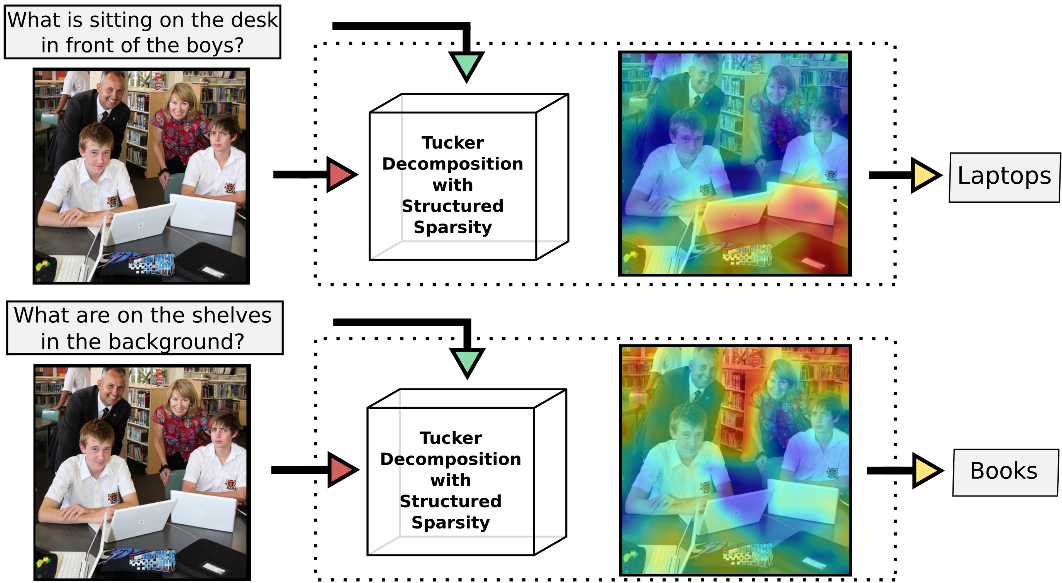
MUTAN: Multimodal Tucker Fusion for Visual Question Answering
Bilinear models provide an appealing framework for mixing and merging information in Visual Question Answering (VQA) tasks. They help to learn high level associations between question meaning and visual concepts in the image, but they suffer from huge dimensionality issues. We introduce MUTAN, a multimodal tensor-based Tucker decomposition to efficiently parametrize bilinear interactions between visual and textual representations. Additionally to the Tucker framework, we design a low-rank matrix-based decomposition to explicitly constrain the interaction rank. With MUTAN, we control the complexity of the merging scheme while keeping nice interpretable fusion relations. We show how our MUTAN model generalizes some of the latest VQA architectures, providing state-of-the-art results.
PDF Abstract ICCV 2017 PDF ICCV 2017 Abstract


 Visual Question Answering
Visual Question Answering
 Visual Question Answering v2.0
Visual Question Answering v2.0

