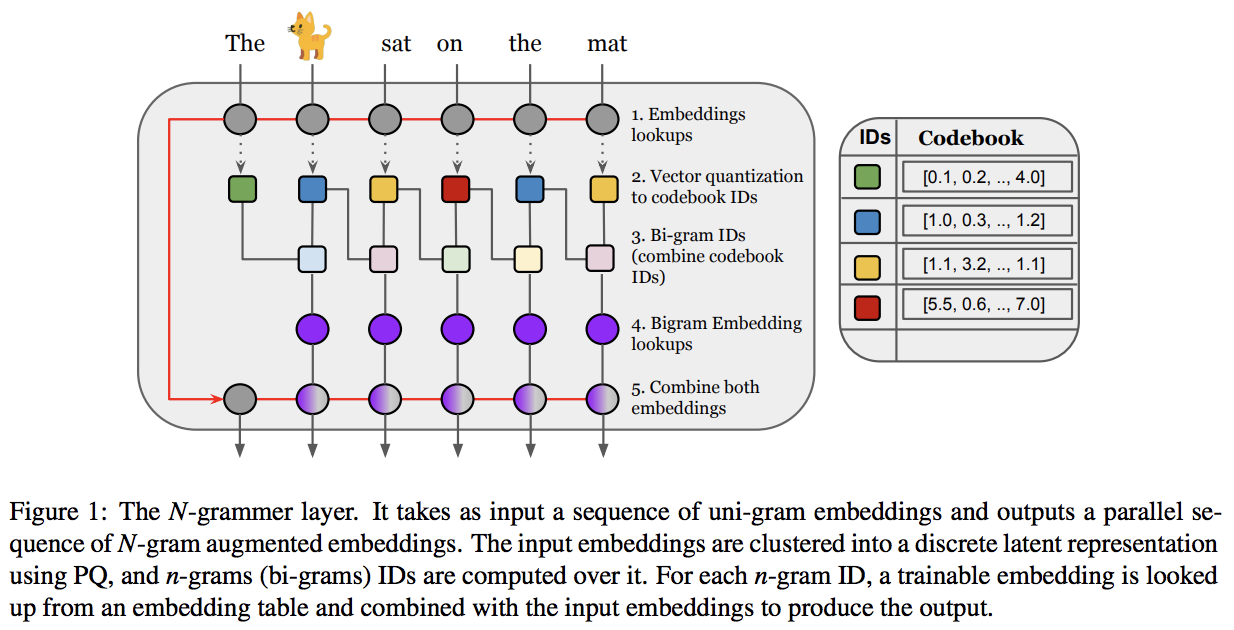
N-Grammer: Augmenting Transformers with latent n-grams
Transformer models have recently emerged as one of the foundational models in natural language processing, and as a byproduct, there is significant recent interest and investment in scaling these models. However, the training and inference costs of these large Transformer language models are prohibitive, thus necessitating more research in identifying more efficient variants. In this work, we propose a simple yet effective modification to the Transformer architecture inspired by the literature in statistical language modeling, by augmenting the model with n-grams that are constructed from a discrete latent representation of the text sequence. We evaluate our model, the N-Grammer on language modeling on the C4 data-set as well as text classification on the SuperGLUE data-set, and find that it outperforms several strong baselines such as the Transformer and the Primer. We open-source our model for reproducibility purposes in Jax.
PDF Abstract Colab
Colab







 GLUE
GLUE
 C4
C4
 BoolQ
BoolQ
 SuperGLUE
SuperGLUE
 WSC
WSC
 COPA
COPA
 MultiRC
MultiRC
 ReCoRD
ReCoRD

