NeoRL: A Near Real-World Benchmark for Offline Reinforcement Learning
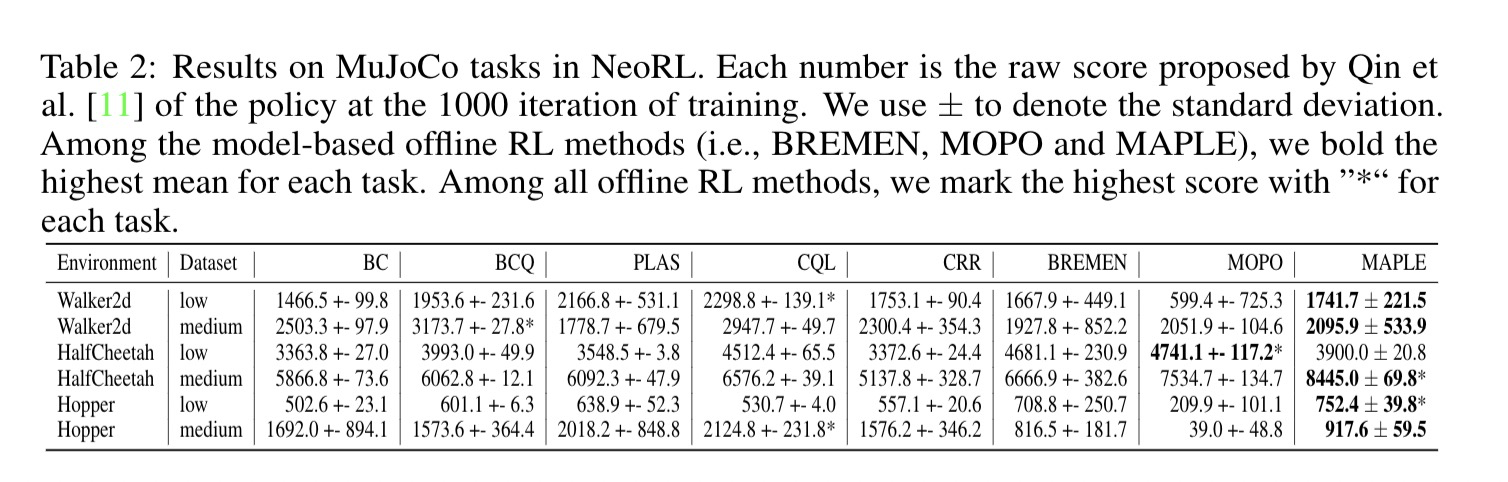
Offline reinforcement learning (RL) aims at learning a good policy from a batch of collected data, without extra interactions with the environment during training. However, current offline RL benchmarks commonly have a large reality gap, because they involve large datasets collected by highly exploratory policies, and the trained policy is directly evaluated in the environment. In real-world situations, running a highly exploratory policy is prohibited to ensure system safety, the data is commonly very limited, and a trained policy should be well validated before deployment. In this paper, we present a near real-world offline RL benchmark, named NeoRL, which contains datasets from various domains with controlled sizes, and extra test datasets for policy validation. We evaluate existing offline RL algorithms on NeoRL and argue that the performance of a policy should also be compared with the deterministic version of the behavior policy, instead of the dataset reward. The empirical results demonstrate that the tested offline RL algorithms become less competitive to the deterministic policy on many datasets, and the offline policy evaluation hardly helps. The NeoRL suit can be found at http://polixir.ai/research/neorl. We hope this work will shed some light on future research and draw more attention when deploying RL in real-world systems.
PDF Abstract


 NeoRL
NeoRL
 MuJoCo
MuJoCo
 D4RL
D4RL
 RL Unplugged
RL Unplugged
