Neural Architecture Search with Random Labels
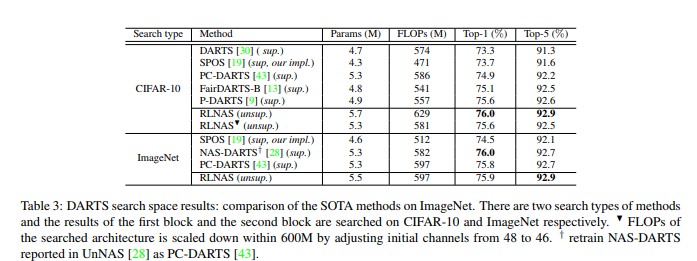
In this paper, we investigate a new variant of neural architecture search (NAS) paradigm -- searching with random labels (RLNAS). The task sounds counter-intuitive for most existing NAS algorithms since random label provides few information on the performance of each candidate architecture. Instead, we propose a novel NAS framework based on ease-of-convergence hypothesis, which requires only random labels during searching. The algorithm involves two steps: first, we train a SuperNet using random labels; second, from the SuperNet we extract the sub-network whose weights change most significantly during the training. Extensive experiments are evaluated on multiple datasets (e.g. NAS-Bench-201 and ImageNet) and multiple search spaces (e.g. DARTS-like and MobileNet-like). Very surprisingly, RLNAS achieves comparable or even better results compared with state-of-the-art NAS methods such as PC-DARTS, Single Path One-Shot, even though the counterparts utilize full ground truth labels for searching. We hope our finding could inspire new understandings on the essential of NAS.
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract

 CIFAR-10
CIFAR-10
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 Cityscapes
Cityscapes
