Learning cross-lingual phonological and orthagraphic adaptations: a case study in improving neural machine translation between low-resource languages
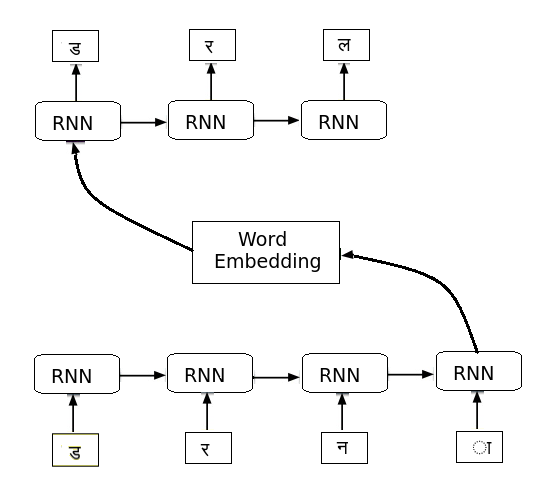
Out-of-vocabulary (OOV) words can pose serious challenges for machine translation (MT) tasks, and in particular, for low-resource language (LRL) pairs, i.e., language pairs for which few or no parallel corpora exist. Our work adapts variants of seq2seq models to perform transduction of such words from Hindi to Bhojpuri (an LRL instance), learning from a set of cognate pairs built from a bilingual dictionary of Hindi--Bhojpuri words. We demonstrate that our models can be effectively used for language pairs that have limited parallel corpora; our models work at the character level to grasp phonetic and orthographic similarities across multiple types of word adaptations, whether synchronic or diachronic, loan words or cognates. We describe the training aspects of several character level NMT systems that we adapted to this task and characterize their typical errors. Our method improves BLEU score by 6.3 on the Hindi-to-Bhojpuri translation task. Further, we show that such transductions can generalize well to other languages by applying it successfully to Hindi -- Bangla cognate pairs. Our work can be seen as an important step in the process of: (i) resolving the OOV words problem arising in MT tasks, (ii) creating effective parallel corpora for resource-constrained languages, and (iii) leveraging the enhanced semantic knowledge captured by word-level embeddings to perform character-level tasks.
PDF Abstract


