NMTScore: A Multilingual Analysis of Translation-based Text Similarity Measures
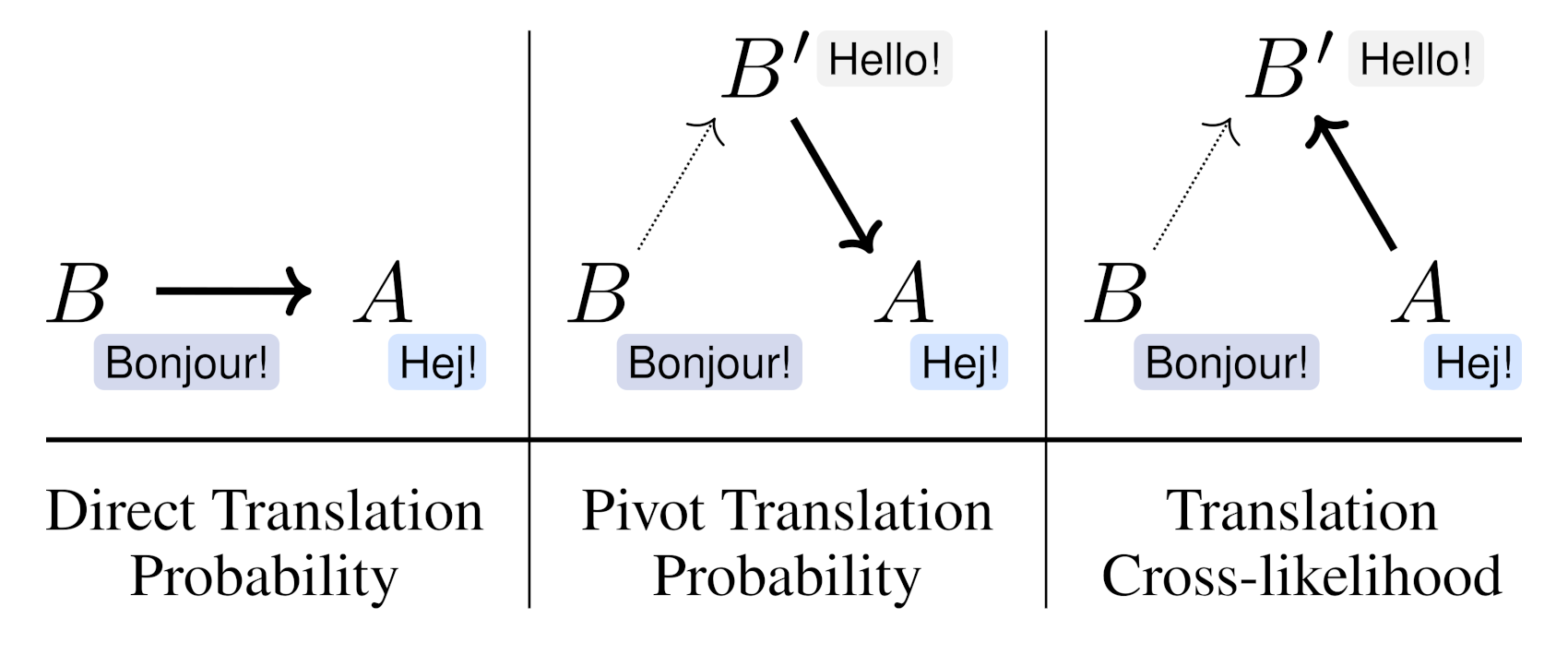
Being able to rank the similarity of short text segments is an interesting bonus feature of neural machine translation. Translation-based similarity measures include direct and pivot translation probability, as well as translation cross-likelihood, which has not been studied so far. We analyze these measures in the common framework of multilingual NMT, releasing the NMTScore library (available at https://github.com/ZurichNLP/nmtscore). Compared to baselines such as sentence embeddings, translation-based measures prove competitive in paraphrase identification and are more robust against adversarial or multilingual input, especially if proper normalization is applied. When used for reference-based evaluation of data-to-text generation in 2 tasks and 17 languages, translation-based measures show a relatively high correlation to human judgments.
PDF Abstract





 PAWS-X
PAWS-X
