No Token Left Behind: Explainability-Aided Image Classification and Generation
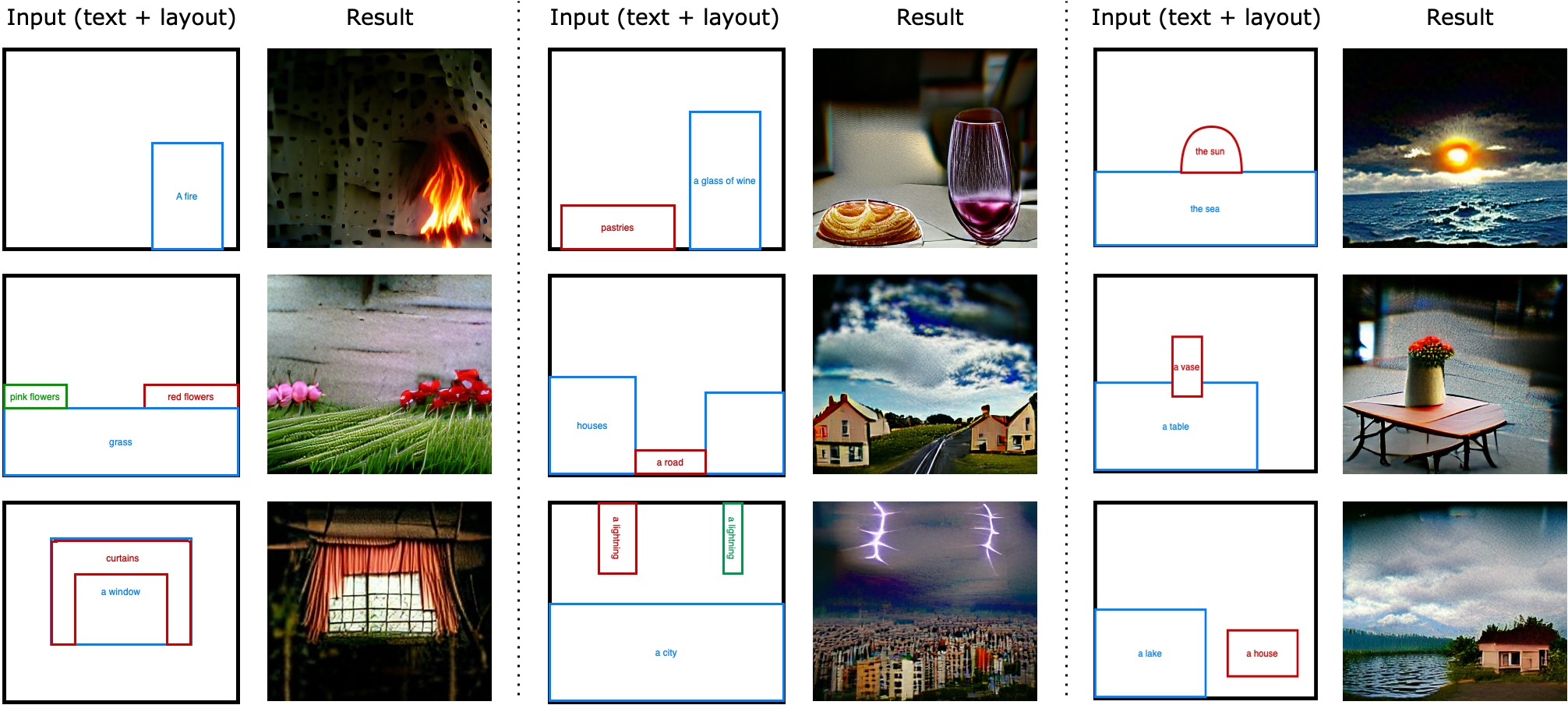
The application of zero-shot learning in computer vision has been revolutionized by the use of image-text matching models. The most notable example, CLIP, has been widely used for both zero-shot classification and guiding generative models with a text prompt. However, the zero-shot use of CLIP is unstable with respect to the phrasing of the input text, making it necessary to carefully engineer the prompts used. We find that this instability stems from a selective similarity score, which is based only on a subset of the semantically meaningful input tokens. To mitigate it, we present a novel explainability-based approach, which adds a loss term to ensure that CLIP focuses on all relevant semantic parts of the input, in addition to employing the CLIP similarity loss used in previous works. When applied to one-shot classification through prompt engineering, our method yields an improvement in the recognition rate, without additional training or fine-tuning. Additionally, we show that CLIP guidance of generative models using our method significantly improves the generated images. Finally, we demonstrate a novel use of CLIP guidance for text-based image generation with spatial conditioning on object location, by requiring the image explainability heatmap for each object to be confined to a pre-determined bounding box.
PDF Abstract Colab
Colab






 MS COCO
MS COCO
 ImageNet-R
ImageNet-R
 ImageNet-A
ImageNet-A
