
Non-deep Networks
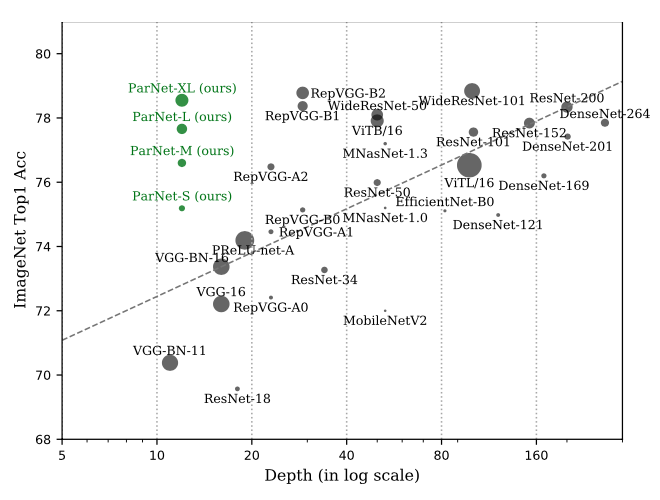
Depth is the hallmark of deep neural networks. But more depth means more sequential computation and higher latency. This begs the question -- is it possible to build high-performing "non-deep" neural networks? We show that it is. To do so, we use parallel subnetworks instead of stacking one layer after another. This helps effectively reduce depth while maintaining high performance. By utilizing parallel substructures, we show, for the first time, that a network with a depth of just 12 can achieve top-1 accuracy over 80% on ImageNet, 96% on CIFAR10, and 81% on CIFAR100. We also show that a network with a low-depth (12) backbone can achieve an AP of 48% on MS-COCO. We analyze the scaling rules for our design and show how to increase performance without changing the network's depth. Finally, we provide a proof of concept for how non-deep networks could be used to build low-latency recognition systems. Code is available at https://github.com/imankgoyal/NonDeepNetworks.
PDF Abstract




 ImageNet
ImageNet
 MS COCO
MS COCO
