Non-Parallel Sequence-to-Sequence Voice Conversion with Disentangled Linguistic and Speaker Representations
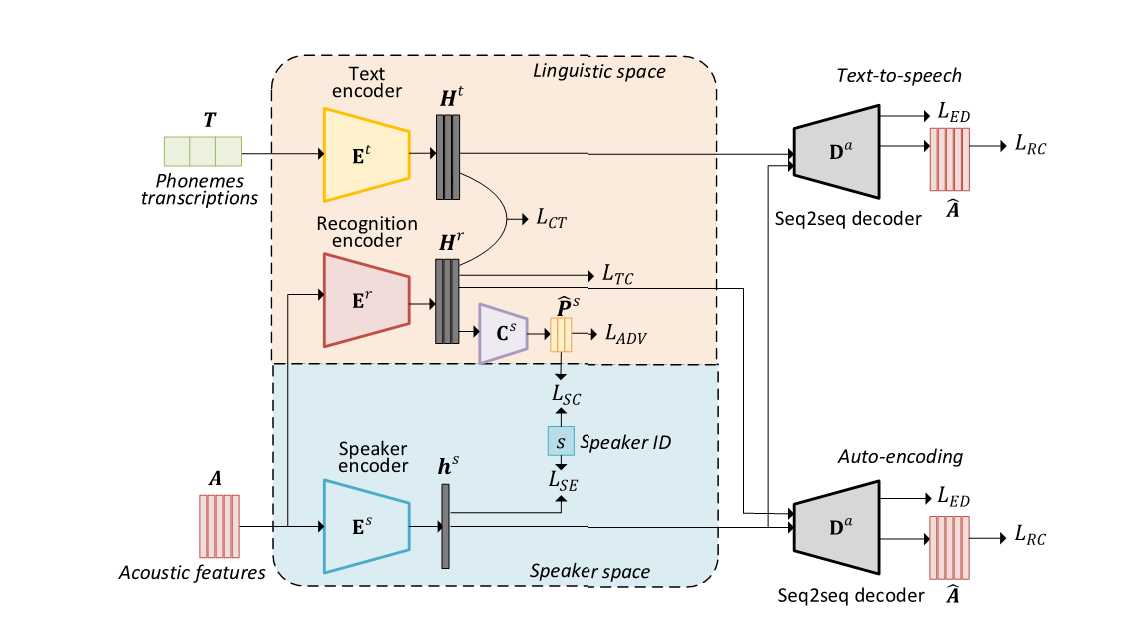
This paper presents a method of sequence-to-sequence (seq2seq) voice conversion using non-parallel training data. In this method, disentangled linguistic and speaker representations are extracted from acoustic features, and voice conversion is achieved by preserving the linguistic representations of source utterances while replacing the speaker representations with the target ones. Our model is built under the framework of encoder-decoder neural networks. A recognition encoder is designed to learn the disentangled linguistic representations with two strategies. First, phoneme transcriptions of training data are introduced to provide the references for leaning linguistic representations of audio signals. Second, an adversarial training strategy is employed to further wipe out speaker information from the linguistic representations. Meanwhile, speaker representations are extracted from audio signals by a speaker encoder. The model parameters are estimated by two-stage training, including a pretraining stage using a multi-speaker dataset and a fine-tuning stage using the dataset of a specific conversion pair. Since both the recognition encoder and the decoder for recovering acoustic features are seq2seq neural networks, there are no constrains of frame alignment and frame-by-frame conversion in our proposed method. Experimental results showed that our method obtained higher similarity and naturalness than the best non-parallel voice conversion method in Voice Conversion Challenge 2018. Besides, the performance of our proposed method was closed to the state-of-the-art parallel seq2seq voice conversion method.
PDF Abstract
