Non-stationary Bandits and Meta-Learning with a Small Set of Optimal Arms
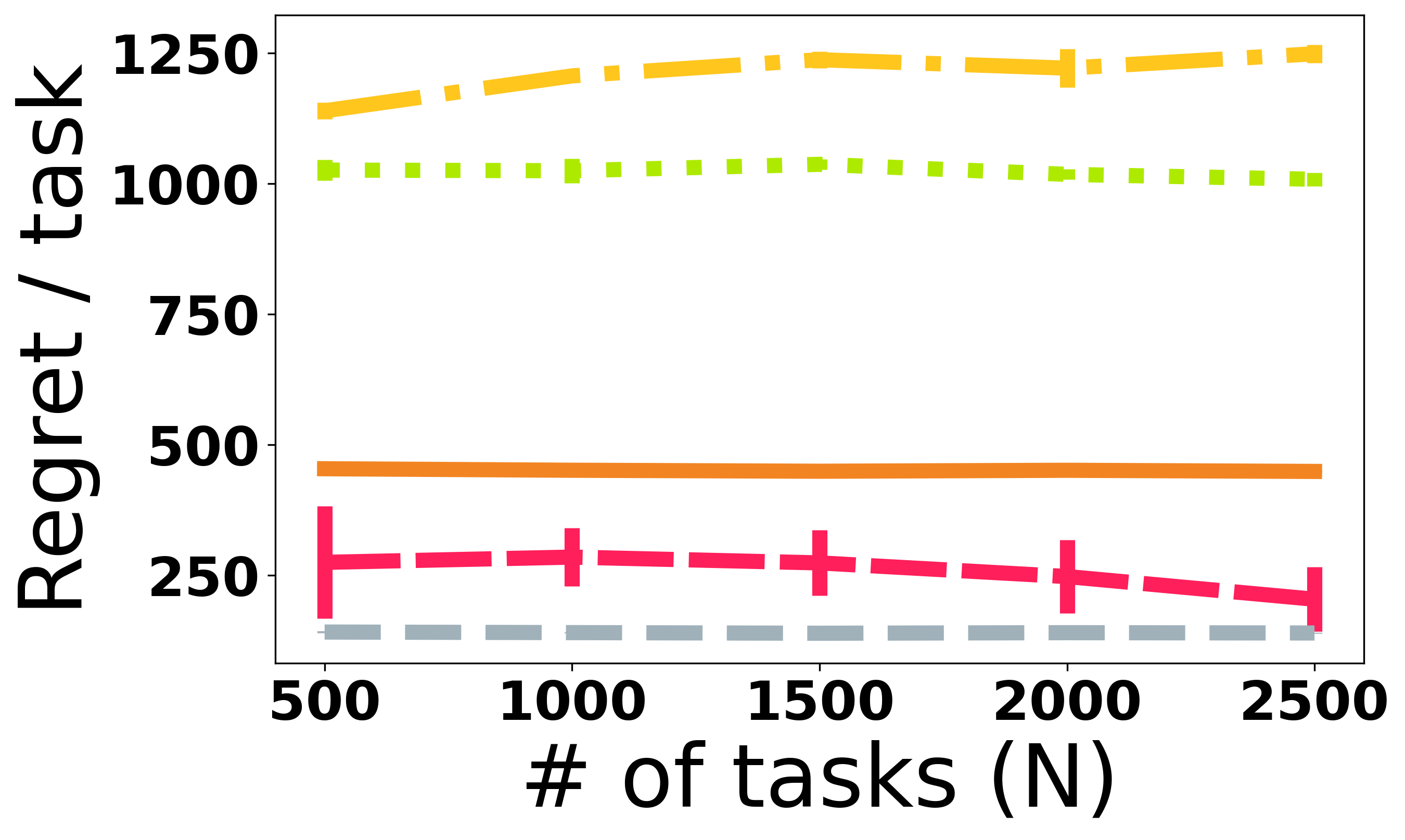
We study a sequential decision problem where the learner faces a sequence of $K$-armed bandit tasks. The task boundaries might be known (the bandit meta-learning setting), or unknown (the non-stationary bandit setting). For a given integer $M\le K$, the learner aims to compete with the best subset of arms of size $M$. We design an algorithm based on a reduction to bandit submodular maximization, and show that, for $T$ rounds comprised of $N$ tasks, in the regime of large number of tasks and small number of optimal arms $M$, its regret in both settings is smaller than the simple baseline of $\tilde{O}(\sqrt{KNT})$ that can be obtained by using standard algorithms designed for non-stationary bandit problems. For the bandit meta-learning problem with fixed task length $\tau$, we show that the regret of the algorithm is bounded as $\tilde{O}(NM\sqrt{M \tau}+N^{2/3}M\tau)$. Under additional assumptions on the identifiability of the optimal arms in each task, we show a bandit meta-learning algorithm with an improved $\tilde{O}(N\sqrt{M \tau}+N^{1/2}\sqrt{M K \tau})$ regret.
PDF Abstract
