Not All Features Matter: Enhancing Few-shot CLIP with Adaptive Prior Refinement
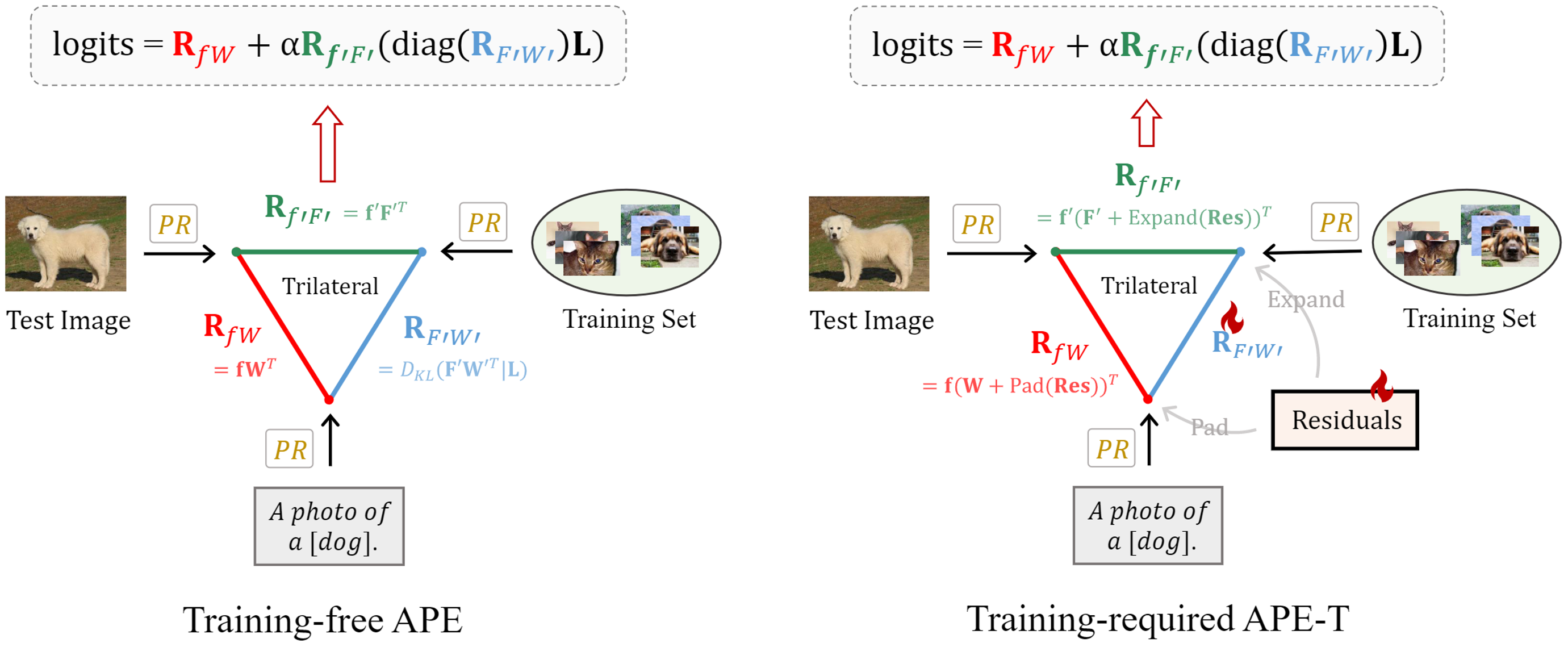
The popularity of Contrastive Language-Image Pre-training (CLIP) has propelled its application to diverse downstream vision tasks. To improve its capacity on downstream tasks, few-shot learning has become a widely-adopted technique. However, existing methods either exhibit limited performance or suffer from excessive learnable parameters. In this paper, we propose APE, an Adaptive Prior rEfinement method for CLIP's pre-trained knowledge, which achieves superior accuracy with high computational efficiency. Via a prior refinement module, we analyze the inter-class disparity in the downstream data and decouple the domain-specific knowledge from the CLIP-extracted cache model. On top of that, we introduce two model variants, a training-free APE and a training-required APE-T. We explore the trilateral affinities between the test image, prior cache model, and textual representations, and only enable a lightweight category-residual module to be trained. For the average accuracy over 11 benchmarks, both APE and APE-T attain state-of-the-art and respectively outperform the second-best by +1.59% and +1.99% under 16 shots with x30 less learnable parameters.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract

 ImageNet
ImageNet
 DTD
DTD
 Food-101
Food-101
 EuroSAT
EuroSAT
 FGVC-Aircraft
FGVC-Aircraft
 ImageNet-Sketch
ImageNet-Sketch
