Not All Images are Worth 16x16 Words: Dynamic Transformers for Efficient Image Recognition
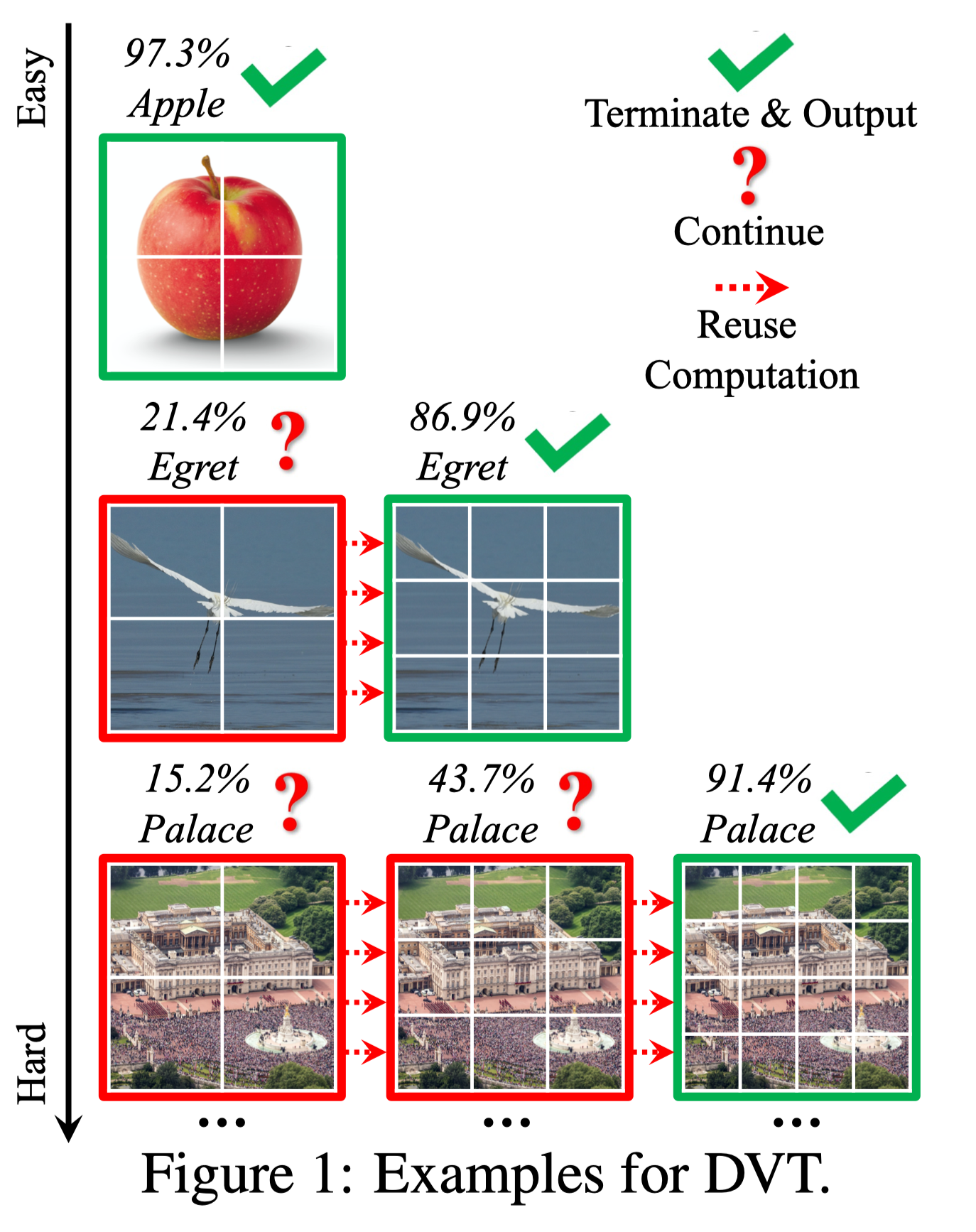
Vision Transformers (ViT) have achieved remarkable success in large-scale image recognition. They split every 2D image into a fixed number of patches, each of which is treated as a token. Generally, representing an image with more tokens would lead to higher prediction accuracy, while it also results in drastically increased computational cost. To achieve a decent trade-off between accuracy and speed, the number of tokens is empirically set to 16x16 or 14x14. In this paper, we argue that every image has its own characteristics, and ideally the token number should be conditioned on each individual input. In fact, we have observed that there exist a considerable number of "easy" images which can be accurately predicted with a mere number of 4x4 tokens, while only a small fraction of "hard" ones need a finer representation. Inspired by this phenomenon, we propose a Dynamic Transformer to automatically configure a proper number of tokens for each input image. This is achieved by cascading multiple Transformers with increasing numbers of tokens, which are sequentially activated in an adaptive fashion at test time, i.e., the inference is terminated once a sufficiently confident prediction is produced. We further design efficient feature reuse and relationship reuse mechanisms across different components of the Dynamic Transformer to reduce redundant computations. Extensive empirical results on ImageNet, CIFAR-10, and CIFAR-100 demonstrate that our method significantly outperforms the competitive baselines in terms of both theoretical computational efficiency and practical inference speed. Code and pre-trained models (based on PyTorch and MindSpore) are available at https://github.com/blackfeather-wang/Dynamic-Vision-Transformer and https://github.com/blackfeather-wang/Dynamic-Vision-Transformer-MindSpore.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 AbstractCode




 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
Results from the Paper
 Ranked #29 on
Image Classification
on CIFAR-100
(using extra training data)
Ranked #29 on
Image Classification
on CIFAR-100
(using extra training data)
