NukeBERT: A Pre-trained language model for Low Resource Nuclear Domain
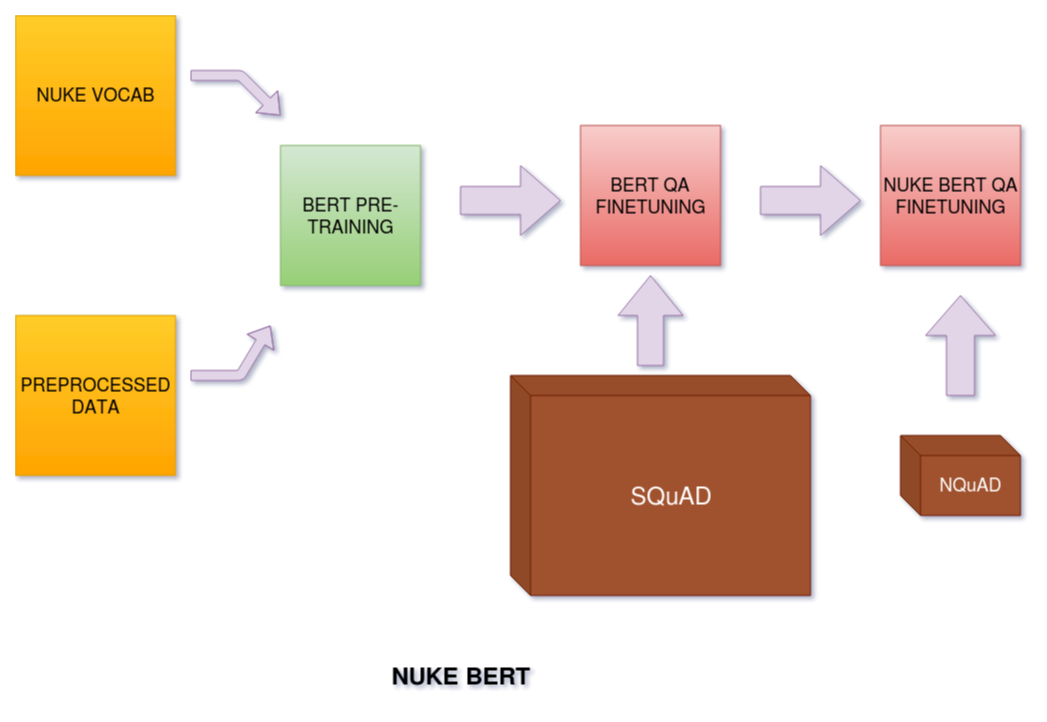
Significant advances have been made in recent years on Natural Language Processing with machines surpassing human performance in many tasks, including but not limited to Question Answering. The majority of deep learning methods for Question Answering targets domains with large datasets and highly matured literature. The area of Nuclear and Atomic energy has largely remained unexplored in exploiting non-annotated data for driving industry viable applications. Due to lack of dataset, a new dataset was created from the 7000 research papers on nuclear domain. This paper contributes to research in understanding nuclear domain knowledge which is then evaluated on Nuclear Question Answering Dataset (NQuAD) created by nuclear domain experts as part of this research. NQuAD contains 612 questions developed on 181 paragraphs randomly selected from the IGCAR research paper corpus. In this paper, the Nuclear Bidirectional Encoder Representational Transformers (NukeBERT) is proposed, which incorporates a novel technique for building BERT vocabulary to make it suitable for tasks with less training data. The experiments evaluated on NQuAD revealed that NukeBERT was able to outperform BERT significantly, thus validating the adopted methodology. Training NukeBERT is computationally expensive and hence we will be open-sourcing the NukeBERT pretrained weights and NQuAD for fostering further research work in the nuclear domain.
PDF Abstract

 NQuAD
NQuAD
 NText
NText
 SQuAD
SQuAD
