NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
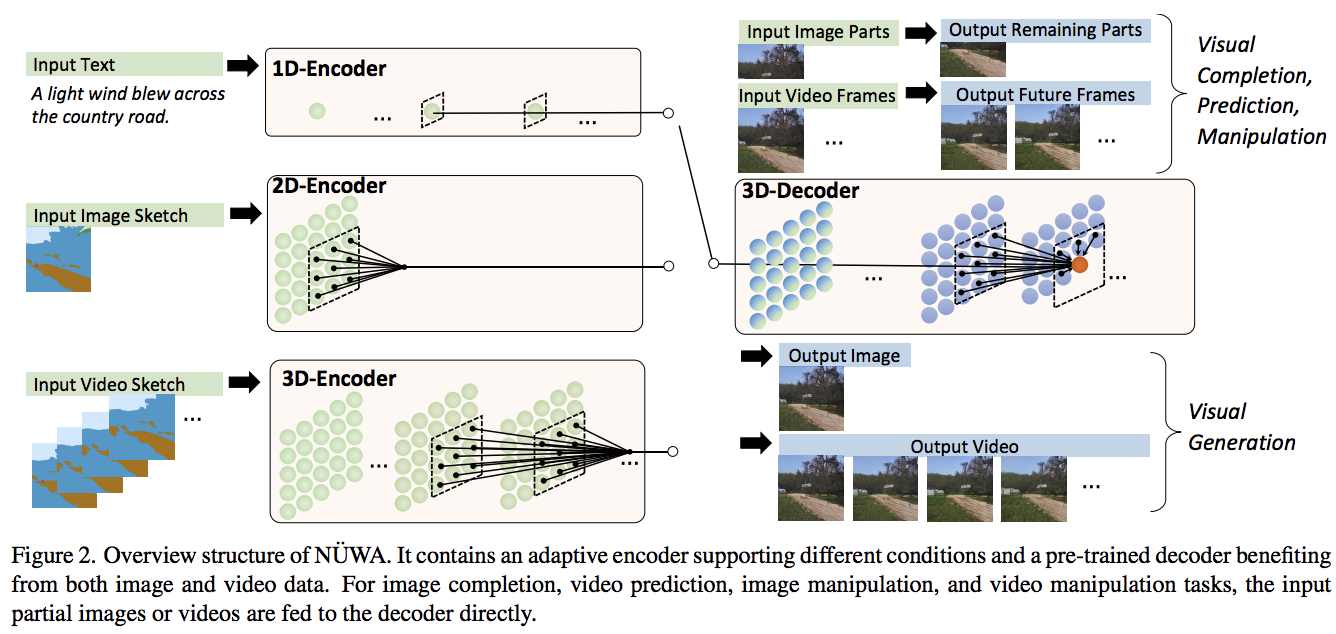
This paper presents a unified multimodal pre-trained model called N\"UWA that can generate new or manipulate existing visual data (i.e., images and videos) for various visual synthesis tasks. To cover language, image, and video at the same time for different scenarios, a 3D transformer encoder-decoder framework is designed, which can not only deal with videos as 3D data but also adapt to texts and images as 1D and 2D data, respectively. A 3D Nearby Attention (3DNA) mechanism is also proposed to consider the nature of the visual data and reduce the computational complexity. We evaluate N\"UWA on 8 downstream tasks. Compared to several strong baselines, N\"UWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, etc. Furthermore, it also shows surprisingly good zero-shot capabilities on text-guided image and video manipulation tasks. Project repo is https://github.com/microsoft/NUWA.
PDF Abstract





 MS COCO
MS COCO
 Kinetics
Kinetics
 MSR-VTT
MSR-VTT

