Obj2Seq: Formatting Objects as Sequences with Class Prompt for Visual Tasks
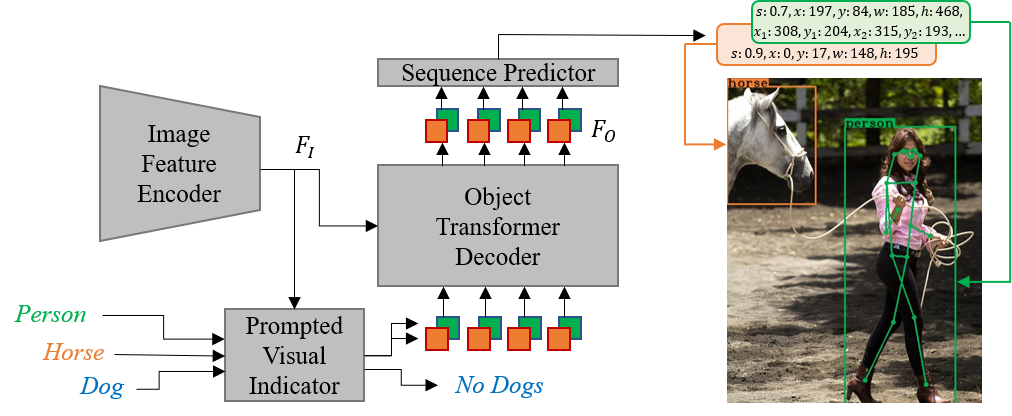
Visual tasks vary a lot in their output formats and concerned contents, therefore it is hard to process them with an identical structure. One main obstacle lies in the high-dimensional outputs in object-level visual tasks. In this paper, we propose an object-centric vision framework, Obj2Seq. Obj2Seq takes objects as basic units, and regards most object-level visual tasks as sequence generation problems of objects. Therefore, these visual tasks can be decoupled into two steps. First recognize objects of given categories, and then generate a sequence for each of these objects. The definition of the output sequences varies for different tasks, and the model is supervised by matching these sequences with ground-truth targets. Obj2Seq is able to flexibly determine input categories to satisfy customized requirements, and be easily extended to different visual tasks. When experimenting on MS COCO, Obj2Seq achieves 45.7% AP on object detection, 89.0% AP on multi-label classification and 65.0% AP on human pose estimation. These results demonstrate its potential to be generally applied to different visual tasks. Code has been made available at: https://github.com/CASIA-IVA-Lab/Obj2Seq.
PDF Abstract



 MS COCO
MS COCO
