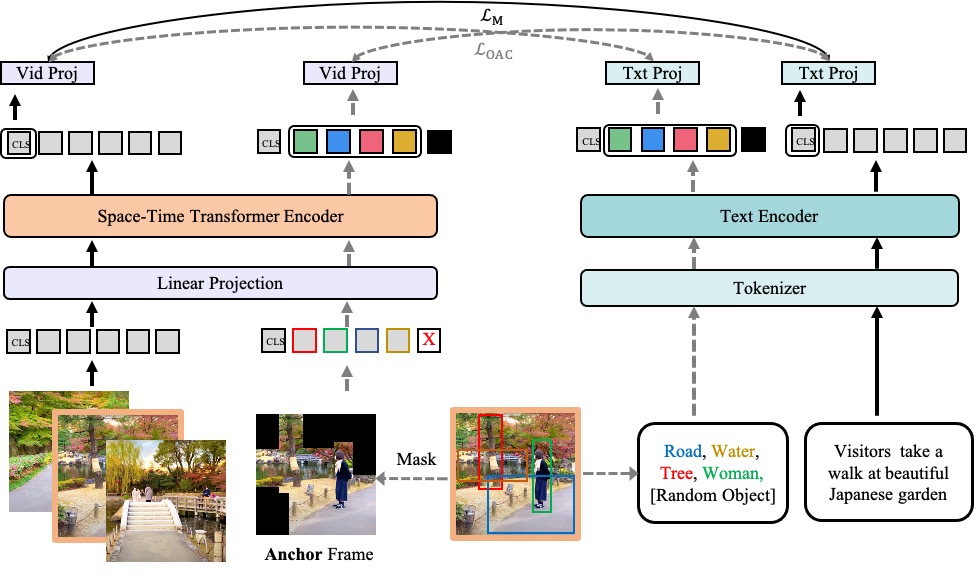
Object-aware Video-language Pre-training for Retrieval
Recently, by introducing large-scale dataset and strong transformer network, video-language pre-training has shown great success especially for retrieval. Yet, existing video-language transformer models do not explicitly fine-grained semantic align. In this work, we present Object-aware Transformers, an object-centric approach that extends video-language transformer to incorporate object representations. The key idea is to leverage the bounding boxes and object tags to guide the training process. We evaluate our model on three standard sub-tasks of video-text matching on four widely used benchmarks. We also provide deep analysis and detailed ablation about the proposed method. We show clear improvement in performance across all tasks and datasets considered, demonstrating the value of a model that incorporates object representations into a video-language architecture. The code will be released at \url{https://github.com/FingerRec/OA-Transformer}.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract

 Kinetics
Kinetics
 Visual Genome
Visual Genome
 MSR-VTT
MSR-VTT
 MSVD
MSVD
 HowTo100M
HowTo100M
 DiDeMo
DiDeMo
 WebVid
WebVid
 LSMDC
LSMDC

