Object-driven Text-to-Image Synthesis via Adversarial Training
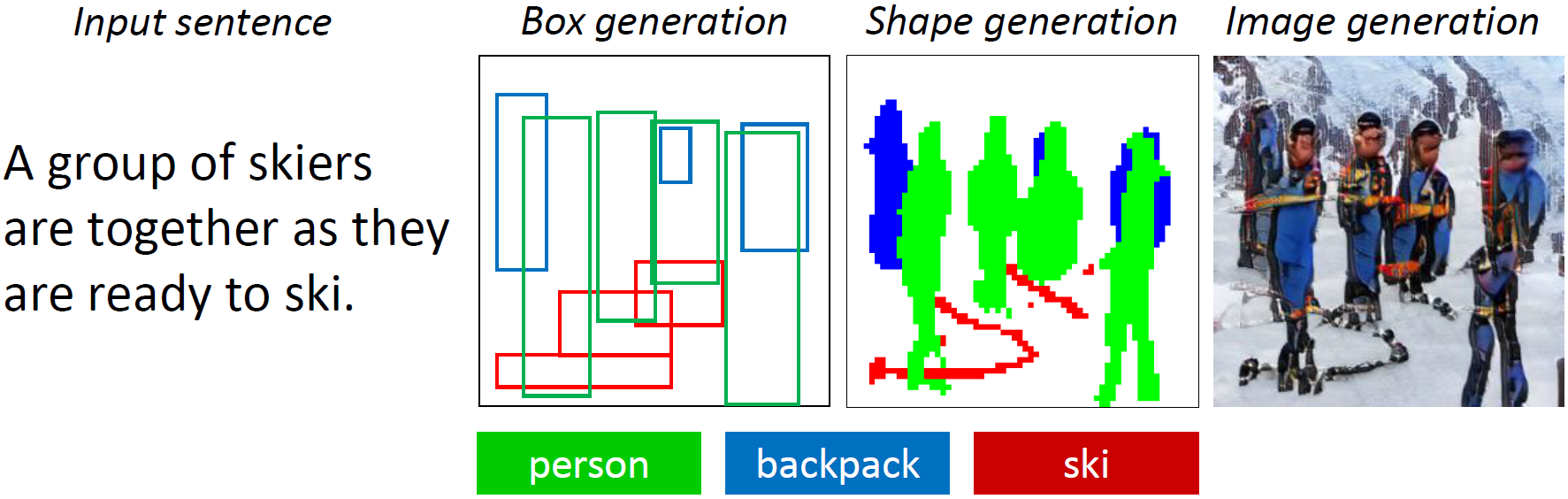
In this paper, we propose Object-driven Attentive Generative Adversarial Newtorks (Obj-GANs) that allow object-centered text-to-image synthesis for complex scenes. Following the two-step (layout-image) generation process, a novel object-driven attentive image generator is proposed to synthesize salient objects by paying attention to the most relevant words in the text description and the pre-generated semantic layout. In addition, a new Fast R-CNN based object-wise discriminator is proposed to provide rich object-wise discrimination signals on whether the synthesized object matches the text description and the pre-generated layout. The proposed Obj-GAN significantly outperforms the previous state of the art in various metrics on the large-scale COCO benchmark, increasing the Inception score by 27% and decreasing the FID score by 11%. A thorough comparison between the traditional grid attention and the new object-driven attention is provided through analyzing their mechanisms and visualizing their attention layers, showing insights of how the proposed model generates complex scenes in high quality.
PDF Abstract CVPR 2019 PDF CVPR 2019 Abstract


 MS COCO
MS COCO
