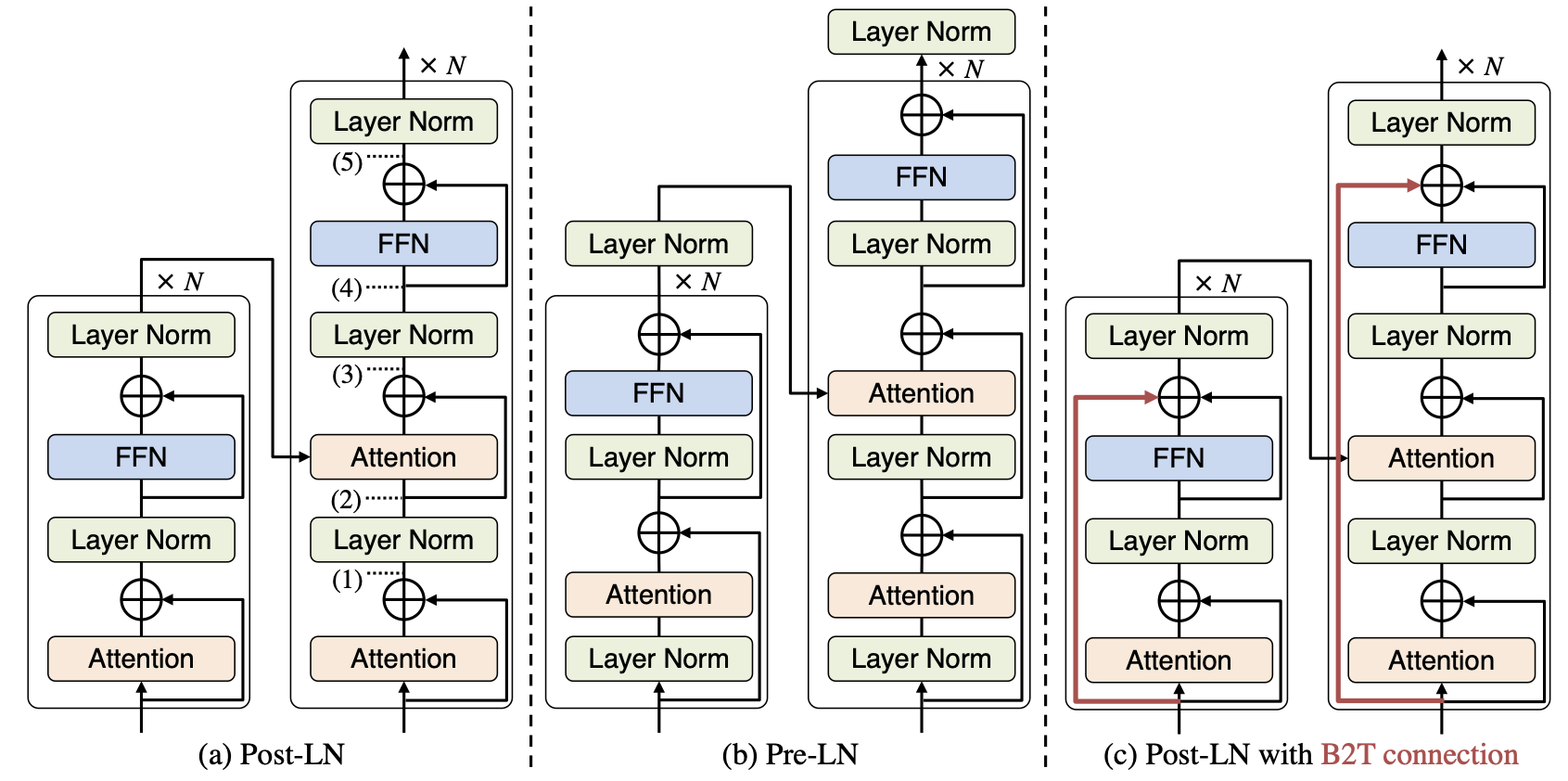
B2T Connection: Serving Stability and Performance in Deep Transformers
From the perspective of the layer normalization (LN) positions, the architectures of Transformers can be categorized into two types: Post-LN and Pre-LN. Recent Transformers tend to be Pre-LN because, in Post-LN with deep Transformers (e.g., those with ten or more layers), the training is often unstable, resulting in useless models. However, Post-LN has consistently achieved better performance than Pre-LN in relatively shallow Transformers (e.g., those with six or fewer layers). This study first investigates the reason for these discrepant observations empirically and theoretically and made the following discoveries: 1, the LN in Post-LN is the main source of the vanishing gradient problem that leads to unstable training, whereas Pre-LN prevents it, and 2, Post-LN tends to preserve larger gradient norms in higher layers during the back-propagation, which may lead to effective training. Exploiting the new findings, we propose a method that can provide both high stability and effective training by a simple modification of Post-LN. We conduct experiments on a wide range of text generation tasks. The experimental results demonstrate that our method outperforms Pre-LN, and enables stable training regardless of the shallow or deep layer settings. Our code is publicly available at https://github.com/takase/b2t_connection.
PDF Abstract

 LibriSpeech
LibriSpeech
 WikiText-2
WikiText-2
 WikiText-103
WikiText-103
