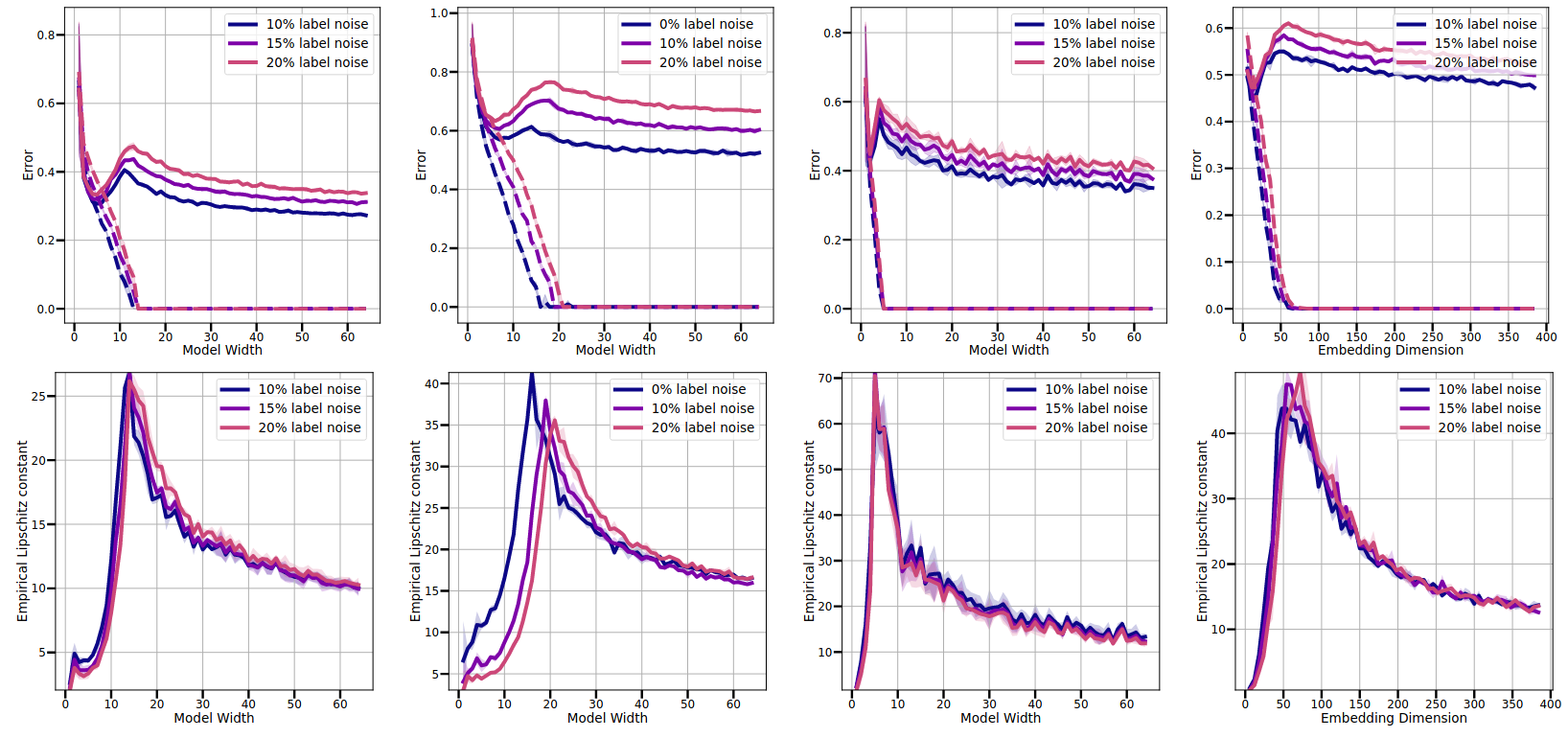
On the Lipschitz Constant of Deep Networks and Double Descent
Existing bounds on the generalization error of deep networks assume some form of smooth or bounded dependence on the input variable, falling short of investigating the mechanisms controlling such factors in practice. In this work, we present an extensive experimental study of the empirical Lipschitz constant of deep networks undergoing double descent, and highlight non-monotonic trends strongly correlating with the test error. Building a connection between parameter-space and input-space gradients for SGD around a critical point, we isolate two important factors -- namely loss landscape curvature and distance of parameters from initialization -- respectively controlling optimization dynamics around a critical point and bounding model function complexity, even beyond the training data. Our study presents novels insights on implicit regularization via overparameterization, and effective model complexity for networks trained in practice.
PDF Abstract
 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
