One Model, Many Languages: Meta-learning for Multilingual Text-to-Speech
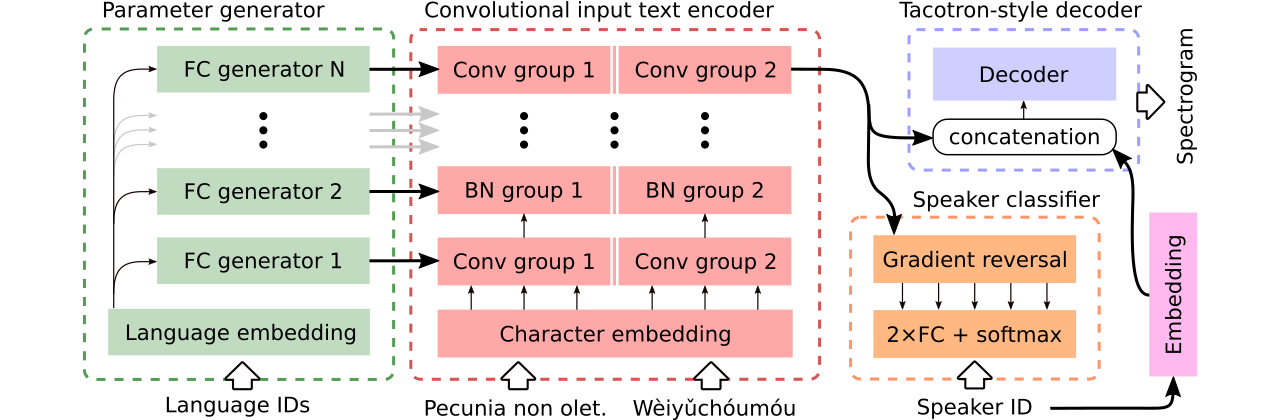
We introduce an approach to multilingual speech synthesis which uses the meta-learning concept of contextual parameter generation and produces natural-sounding multilingual speech using more languages and less training data than previous approaches. Our model is based on Tacotron 2 with a fully convolutional input text encoder whose weights are predicted by a separate parameter generator network. To boost voice cloning, the model uses an adversarial speaker classifier with a gradient reversal layer that removes speaker-specific information from the encoder. We arranged two experiments to compare our model with baselines using various levels of cross-lingual parameter sharing, in order to evaluate: (1) stability and performance when training on low amounts of data, (2) pronunciation accuracy and voice quality of code-switching synthesis. For training, we used the CSS10 dataset and our new small dataset based on Common Voice recordings in five languages. Our model is shown to effectively share information across languages and according to a subjective evaluation test, it produces more natural and accurate code-switching speech than the baselines.
PDF Abstract Colab
Colab




 Common Voice
Common Voice
