One Question Answering Model for Many Languages with Cross-lingual Dense Passage Retrieval
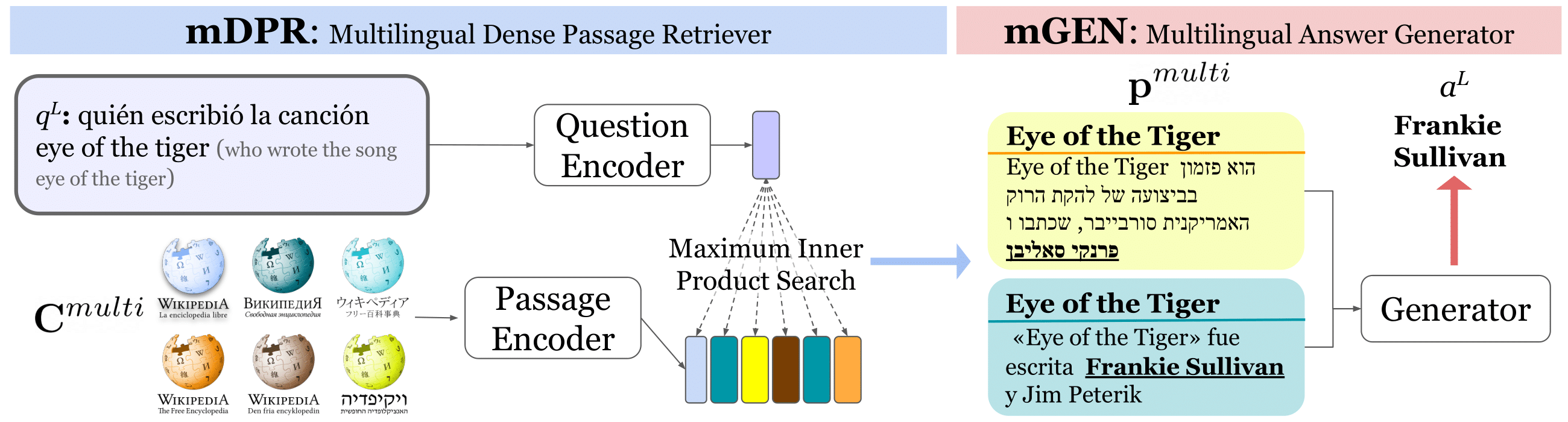
We present Cross-lingual Open-Retrieval Answer Generation (CORA), the first unified many-to-many question answering (QA) model that can answer questions across many languages, even for ones without language-specific annotated data or knowledge sources. We introduce a new dense passage retrieval algorithm that is trained to retrieve documents across languages for a question. Combined with a multilingual autoregressive generation model, CORA answers directly in the target language without any translation or in-language retrieval modules as used in prior work. We propose an iterative training method that automatically extends annotated data available only in high-resource languages to low-resource ones. Our results show that CORA substantially outperforms the previous state of the art on multilingual open QA benchmarks across 26 languages, 9 of which are unseen during training. Our analyses show the significance of cross-lingual retrieval and generation in many languages, particularly under low-resource settings.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract


 Natural Questions
Natural Questions
 MKQA
MKQA
